AverageShiftedHistograms.jl
An Averaged Shifted Histogram (ASH) is essentially Kernel Density Estimation over a fine-partition histogram. ASH uses constant memory, can be constructed on-line via O(nbins) updates, and lets you estimate densities for arbitrarily big data.
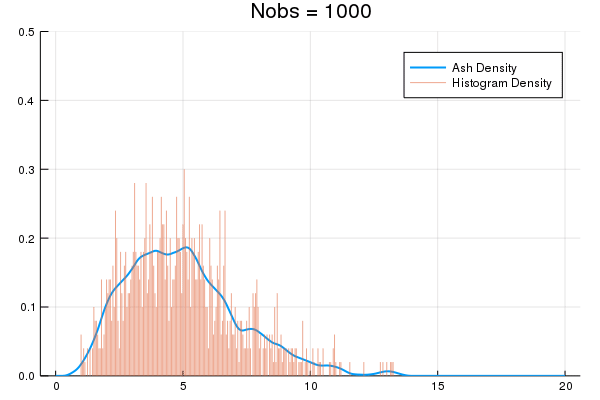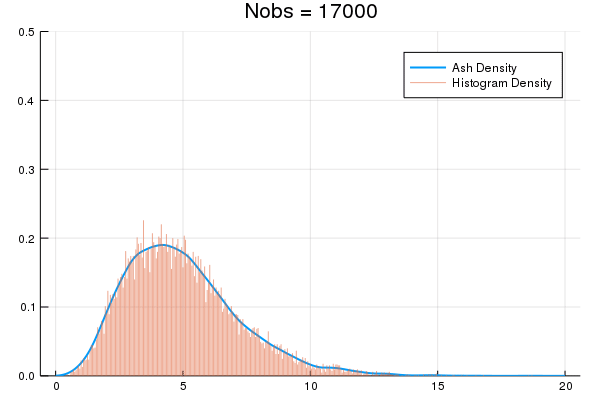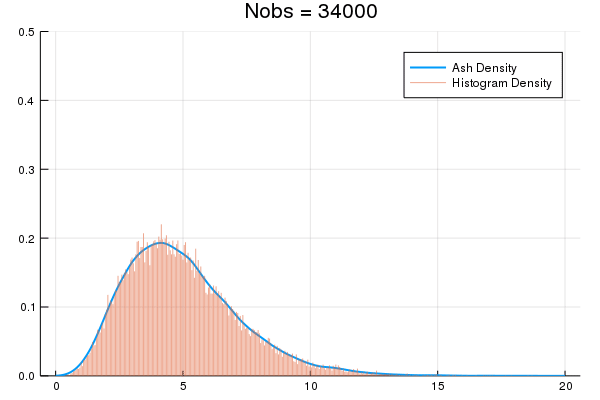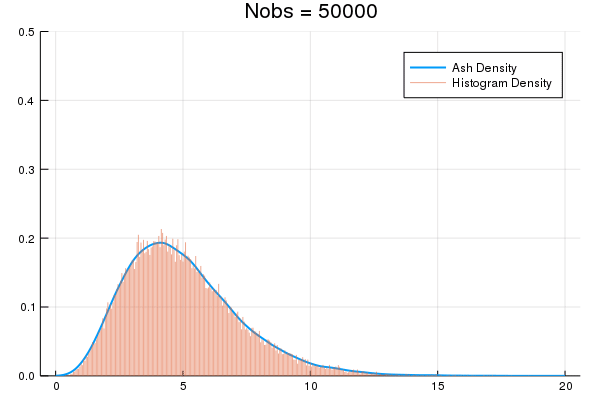
| Docs | Build | Test |
|---|---|---|
 |
Quickstart:
import Pkg
Pkg.add("AverageShiftedHistograms")
using AverageShiftedHistograms
ash(randn(10^6))