EasySparse
Motivation
In production environments, we find TensorFlow poorly deals with sparse learning scenarios. Even when one reads out records from a TFRecord file, feeding the records into a deep learning model can be a hard-bone. Thus, we have open-sourced this project to help researches or engineers build their own model using sparse data while hiding the difficulties.
This project naturally fits into scenarios when one uses TensorFlow to build deep learning models by data acquired from Spark. Other scenarios can be easily generalized.
Data Flow
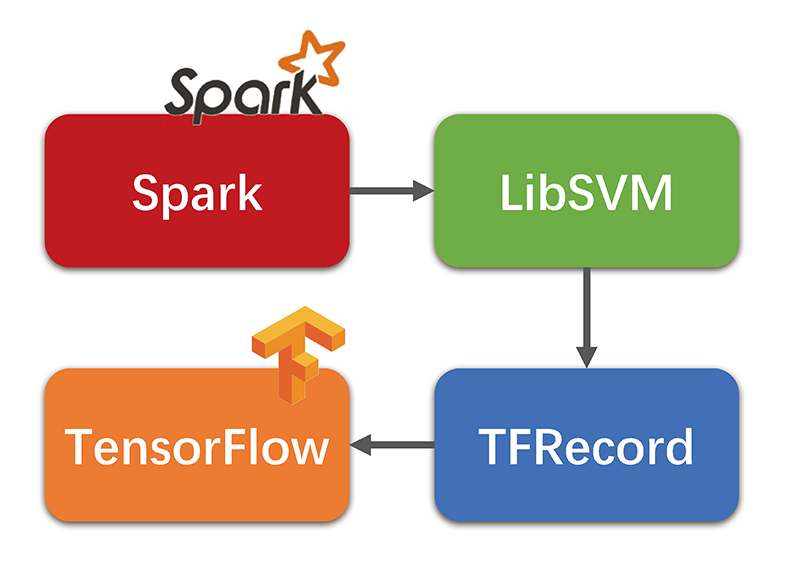
Programs
spark_to_libsvm.scala Read data from Spark to a LibSVM file while one-hot encode features by demand.
libsvm_to_tfrecord.py Convert a LibSVM file into a TFRecord.
train.py Training code for fully connected NN with multi-GPU support.
test.py Test the performance of the trained model.
utils.py Contains all the functions used in training and testing.
Usage
- Read data from Spark, one-hot encode some features, and write them into a LibSVM file. Be sure to manually split the data into three LibSVM files, each for training, validating and testing (
spark_to_libsvm.scala). - Transform the training LibSVM file into TFRecord (
libsvm_to_tfrecord.py). - Run the training program (
train.py). - Test the trained model (
test.py).
Environment
- Spark v2.0
- TensorFlow >= v0.12.1
Python Package Requirements
- Numpy (required)
- Sci-kit Learn (only required in
test.py) - TensorFlow (required, >= v0.12.1)
Implementation Notes
- In the training process,
train.pyreads all the validation data from the LibSVM file into the memory, and harvests shuffled training batches from the TFRecord file. Meanwhile, in the test process, all the test data is read from the LibSVM file. Therefore, one does not need to convert validation and test LibSVM files to TFRecords. However, this implementation may not work when validation and test sets are too large to fit into the memory. Although it rarely happens since validation and test sets are usually much smaller than the training set. If that happens, one need to write TFRecord file queues for validation and test sets. - All the parameters required in the training process are defined at the top of
train.py. Here we use a two-layer FC-NN to model our data. Note that we have adopted AdamOptimizer and exponential decayed learning rate. - One may play with varies types of deep learning models by only modifying the model definition in
train.py.
Contribution
Contributions and comments are welcomed!
Licence
MIT