
ETL
Extract - Transform - Load


Summary
Extract, Transform, Load (ETL) refers to a process in database usage and especially in data warehousing. This repository contains a starter kit featuring ETL related work.
Features and Limitations
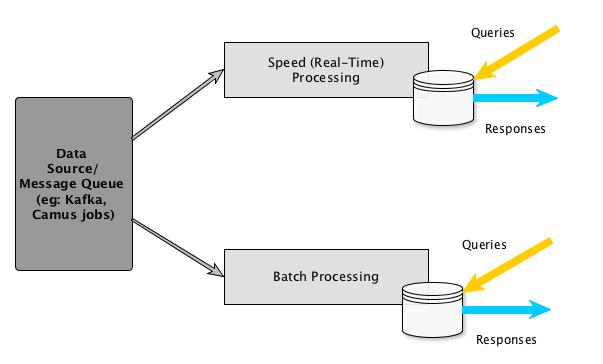
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods.
This starter kit package is mainly focusing on ETL related work where it allows to expand to an independent ETL framework for different client data sources. It contains basic implementation and project structure as follows,
-
Common Module – This will contain all the common jobs and helper classes for ETL framework. Currently two Scalding helper classes are implemented (Hadoop job runner and MapReduceConfig)
-
DataModel Module – This will contain all the BigData schema related code. For example, Avro, ORC, Thrift etc. Currently a sample Avro clickstream raw data shema has been implemented.
-
SampleClient Module – This will contain independent data processing jobs which will have dependency on Common and DataModel.
Since this repository is to keep only the structure; different type of sample jobs are not implemented. Based on your requirement be free to modify and implement different type of batch/streaming jobs (Spark, Hive, Pig etc)
Installation
Make sure you have installed,
- JDK 1.8+
- Scala 2.10.*
- Gradle 2.2+
This started kit package uses the latest version of linkedin gradle Hadoop plugin which supports only gradle 2 series version. If anyone like to use the gradle older version then you have to downgrade linkedin gradle Hadoop plugin.
Directory Layout
.
├── Common --> common module which can contain helper class
│ ├── build.gradle --> build script for common module specific
│ └── src --> source package directory for common module
│ └── main
│ ├── java
│ ├── resources
│ └── scala
│ └── com
│ └── etl
│ └── utils
│ ├── HadoopRunner.scala
│ └── MapReduceConfig.scala
├── DataModel --> schema level module (eg: avro, thrift, json etc)
│ ├── build.gradle --> build script for datamodel module specific
│ ├── schema --> data schema files
│ │ └── com
│ │ └── etl
│ │ └── datamodel
│ │ └── ClickStreamRecord.avsc --> click stream record avro schema
│ ├── src --> source package directory for datamodel module
│ │ └── main
│ │ ├── java
│ │ ├── resources
│ │ └── scala
│ └── target --> auto generated code (eg from avro, thrift etc)
│ └── generated-sources
│ └── main
│ └── java
│ └── com
│ └── etl
│ └── datamodel
│ └── ClickStreamRecord.java --> auto generated code from click stream record avro schema
├── SampleClient --> sperate module for client specific ETL jobs
│ ├── build.gradle --> build script for client specific module
│ ├── src --> source package directory for client specific module
│ │ └── main
│ │ ├── java
│ │ ├── resources
│ │ └── scala
│ │ └── com
│ │ └── sampleclient
│ │ └── jobs
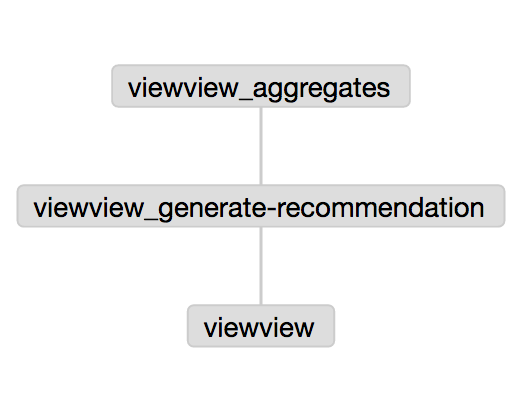
│ │ └── ClickStreamAggregates.scala --> clickstream aggregates jobs
│ └── workflow --> hadoop job flow groovy script folder
│ ├── flow.gradle --> gradle script to generate haoop job flows (eg: Azkaban)
│ └── jobs.gradle --> gradle script for haoop jobs (eg: Azkaban)
├── build.gradle --> build script for root module
├── gradle --> gradle folder which contains all the build script files
│ ├── artifacts.gradle --> artifact file for ETL project
│ ├── buildscript.gradle --> groovy script contains plugins, task classes, and other classes are available for project
│ ├── dependencies.gradle --> dependencies for the ETL project
│ ├── enviroments.groovy --> configuration for prod and dev enviroment
│ ├── repositories.gradle --> all the dependencies repository location
│ └── workflows.gradle --> root workflow gradle file contain configuration and custom build task
├── gradlew
├── gradlew.bat
├── settings.gradle --> setting sub modules
Key Package Links
This starter-kit is made based on few popular libraries with sample code. Based on your requirement choose the suitable technology.
Using The Project
Note: This guide has only been tested on Mac OS X and may assume tools that are specific to it. If working in another OS substitutes may need to be used but should be available.
Step 1 – Build the Project:
- Run
gradle clean build
Once you build the project you will find the following files:
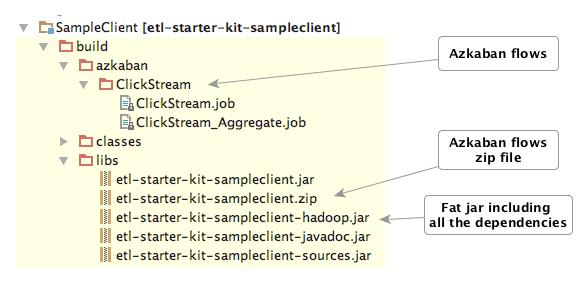
Step 2 – Upload Azkaban Flow
Upload ‘etl-starter-kit-sampleclient.zip’ to Azkaban. After deploying the fat Hadoop jar you’re ready to run the flow.
Notable Frameworks for ETL work:
- Scalding
- Pig
- Hive
- Apache Spark (Batch/Stream data processing)
- Apache Flink (Batch/Stream data processing)
License
MIT © Renien