1.分布式函数调度框架简介
pip install funboost,python全功能分布式函数调度框架,。 支持python所有类型的并发模式和全球一切知名消息队列中间件, python函数加速器,框架包罗万象,一统编程思维,兼容50% python编程业务场景,适用范围广。 只需要一行代码即可分布式执行python一切函数。旧名字是function_scheduling_distributed_framework python万能分布式函数调度框架,支持5种并发模式,30种消息中间件,20种任务控制功能。给任意python函数赋能。 用途概念就是常规经典的 生产者 + 消息队列中间件 + 消费者 编程思想。 框架只需要学习@boost这一个装饰器的入参就可以,所有用法几乎和1.3例子一摸一样,非常简化简单。
框架评价
95%的用户在初步使用后,赞不绝口、相见恨晚。认为funboost框架使用简单但功能强大和丰富。
第一次听说此框架的,100%用户会质疑框架性能不行,功能少,表示学习celery的教程文档上的所有功能
已近非常费劲头疼折磨,各种报错不知道如何解决。
一般python用户听到一个新的python框架,脚都软了,学习类似django celery scrapy意味着要学习
几个月文档才只能掌握框架的一小部分用法了,
尤其是celery这种框架,代码在pycharm完全不能自动补全提示,用户连@task装饰的函数有什么方法,
每个方法有什么入参都不知道,配置文件能写哪些配置都不知道,如果不按照博客上的celery目录结构写celery任务
,连celery命令行运行起来都要反复猜测尝试。
正因为如此用户从心理已近十分惧怕学习一种叫python框架的东西了,用户顶多愿意学习一个python包或者模块,
学习一个框架会非常害怕觉得难度高且耗时,所以非常反感尝试新的框架。
funboost只有一个@boost装饰器,@boost入参能自动补全,更重要的是被@boost装饰的函数,
有哪些方法,每个方法入参是什么都能自动补全。funboost的中间件配置文件自当生成在用户当前项目根目录,
用户无需到处找文档,能配置什么东西,框架功能怎么配置。
因为funboost非常注重代码补全提示,所以不存在上面celery的那些复杂高难度缺点。
funboost的旧框架名字是function_scheduling_distributed_framework , 关系和兼容性见1.0.3介绍。 旧框架地址: https://github.com/ydf0509/distributed_framework
1.0 github地址和文档地址
1.0.1 分布式函数调度框架文档地址
文档很长,但归根结底只需要学习 1.3 里面的这1个例子就行,主要是修改下@boost的各种参数,
通过不同的入参,实践测试下各种控制功能。
对比 celery 有20种改善,其中之一是无依赖文件夹层级和文件夹名字 文件名字。
首先能把 https://github.com/ydf0509/celery_demo
这个例子的已经写好的不规则目录层级和文件名字的函数用celery框架玩起来,才能说是了解celery,
否则如果项目文件夹层级和文件名字不规矩,后期再用celery,会把celery新手折磨得想死,
很多新手需要小心翼翼模仿网上说的项目目录结构,以为不按照那么规划目录和命名就玩不起来,本身说明celery很坑。
1.0.2 分布式函数调度框架github地址
1.0.3 funboost 框架 和 function_scheduling_distributed_framework 框架 关系说明
funboost框架取名说明:
funboost是function_scheduling_distributed_framework框架的新名字,把框架名字长度减小. funboost名字是两个单词,fun是function指的是python函数,boost是加速的意思,合一起是加速函数并发运行.
两个框架的兼容性说明:
funboost 和 function_scheduling_distributed_framework 项目的代码一模一样,以后新代码只更新funboost项目。 from funboost import xx 和 from function_scheduling_distributed_framework import xx 是完全一模一样的. boost是task_deco的别名,两个都可以使用。在消费函数上写@boost 和 @task_deco是一模一样的,两个都可以使用。 所以在有的文档或者截图中如果写 from function_scheduling_distributed_framework import task_deco , @task_deco 用户需要知道效果和from funboost import boost , @boost 是一模一样的。兼容性100%
旧框架地址:function_scheduling_distributed_framework框架地址链接
1.1 安装方式
pip install funboost --upgrade
1.2 框架功能介绍
分布式函数调度框架,支持5种并发模式,20+种消息中间件,20种任务控制功能。
用途概念就是常规经典的 生产者 + 消息队列中间件 + 消费者 编程思想。
有了这个框架,用户再也无需亲自手写操作进程、线程、协程的并发的代码了。
有了这个框架,用户再也无需亲自手写操作redis rabbitmq socket kafka 了。
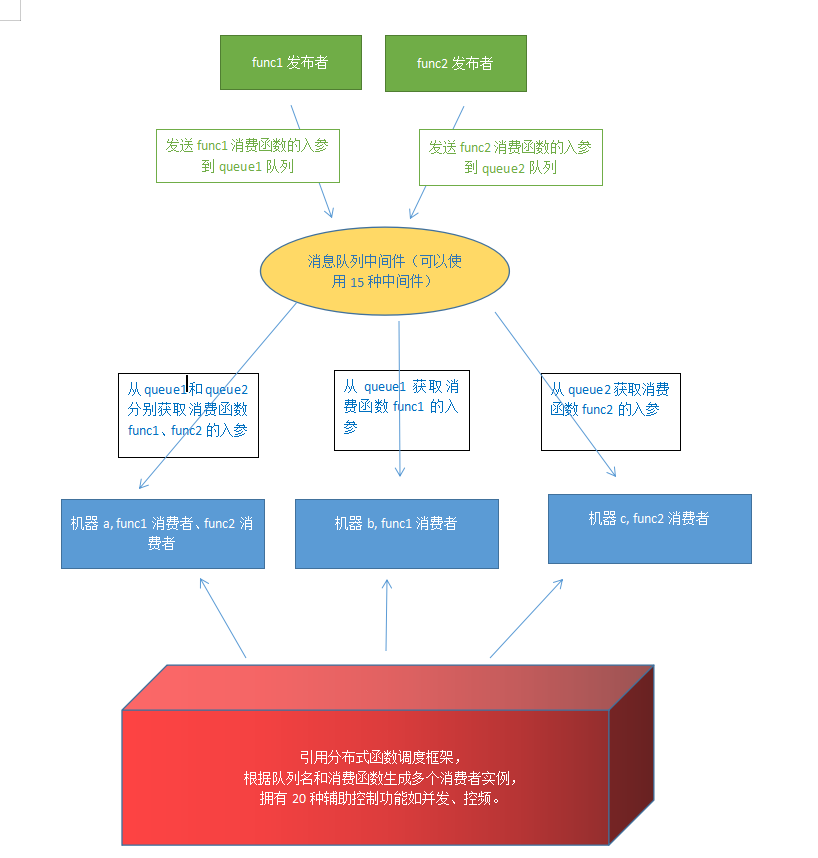
1.2.1 框架支持5种并发模式
总结一下那就是此框架可以适应所有编程场景,无论是io密集 cpu密集 还是cpu io双密集场景,框架能非常简便的应对任意场景。
框架的 单线程 多线程 gevent eventlet asyncio 多进程 这些并发模型,囊括了目前python界所有的并发方式。
框架能自动实现 单线程 ,多线程, gevent , eventlet ,asyncio ,多进程 并发 ,
多进程 + 单线程 ,多进程 + 多线程,多进程 + gevent, 多进程 + eventlet ,多进程 + asyncio 的组合并发
这么多并发方式能够满足任意编程场景。
以下两种方式,都是10线程加python内存queue方式运行f函数,有了此框架,用户无需代码手写手动操作线程 协程 进程并发。
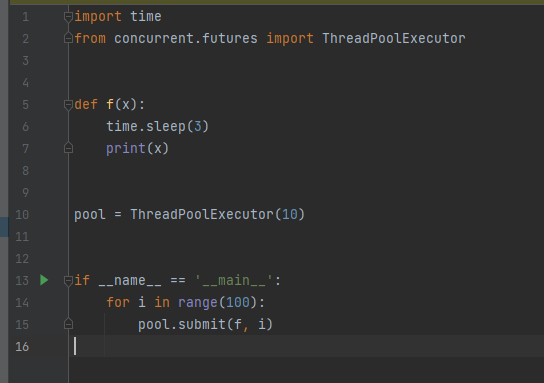
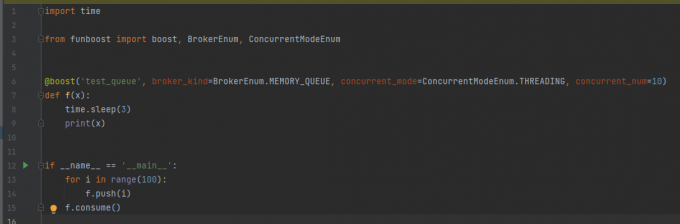
1.2.2 框架支持20种中间件
框架支持 rabbitmq redis python自带的queue.Queue sqlite sqlachemy kafka pulsar mongodb 直接socket 等作为消息中间件。
同时此框架也支持操作 kombu 库作为中间件,所以此框架能够支持的中间件类型只会比celery更多。
框架支持的中间件种类大全和选型见文档3.1章节的介绍:
1.2.3 框架对任务支持20种控制功能。
python通用分布式函数调度框架。适用场景范围广泛, 框架非常适合io密集型(框架支持对函数自动使用 thread gevent eventlet asyncio 并发) 框架非常适合cpu密集型(框架能够在线程 协程基础上 叠加 多进程 multi_process 并发 ,不仅能够多进程执行任务还能多机器执行任务)。 不管是函数需要消耗时io还是消耗cpu,用此框架都很合适,因为任务都是在中间件里面,可以自动分布式分发执行。 此框架是函数的辅助控制倍增器。 框架不适合的场景是 函数极其简单,例如函数只是一行简单的 print hello,函数只需要非常小的cpu和耗时,运行一次函数只消耗了几十hz或者几纳秒, 此时那就采用直接调用函数就好了,因为框架施加了很多控制功能,当框架的运行逻辑耗时耗cpu 远大于函数本身 时候,使用框架反而会使函数执行变慢。 (python框架从全局概念上影响程序的代码组织和运行,包和模块是局部的只影响1个代码文件的几行。) 可以一行代码分布式并发调度起一切任何老代码的旧函数和新项目的新函数,并提供数十种函数控制功能。 还是不懂框架能做什么是什么,就必须先去了解下celery rq。如果连celery rq类似这种的用途概念听都没听说, 那就不可能知道框架的概念和功能用途。
20种控制功能包括:
分布式:
支持数十种最负盛名的消息中间件.(除了常规mq,还包括用不同形式的如 数据库 磁盘文件 redis等来模拟消息队列)
并发:
支持threading gevent eventlet asyncio 单线程 5种并发模式 叠加 多进程。
多进程不是和前面四种模式平行的,是叠加的,例如可以是 多进程 + 协程,多进程 + 多线程。
控频限流:
例如十分精确的指定1秒钟运行30次函数或者0.02次函数(无论函数需要随机运行多久时间,都能精确控制到指定的消费频率;
分布式控频限流:
例如一个脚本反复启动多次或者多台机器多个容器在运行,如果要严格控制总的qps,能够支持分布式控频限流。
任务持久化:
消息队列中间件天然支持
断点接续运行:
无惧反复重启代码,造成任务丢失。消息队列的持久化 + 消费确认机制 做到不丢失一个消息
(此框架很重视消息的万无一失,就是执行函数的机器支持在任何时候随时肆无忌惮反复粗暴拉电闸断电,或者强制硬关机,
或者直接用锄头把执行函数代码的机器砸掉,只要不是暴力破坏安装了消息队列中间件的机器就行,消息就万无一失,
现在很多人做的简单redis list消息队列,以为就叫做分布式断点接续,那是不正确的,因为这种如果把消息从reidis brpop取出来后,
如果消息正在被执行,粗暴的kill -9脚本或者直接强制关机,那么正在运行的消息就丢失了,如果是多线程同时并发运行很多消息,粗暴重启
会丢失几百个大量消息,这种简单的redis list根本就不能叫做安全的断点续传。
分布式函数调度框架的消费确认机制,保证函数运行完了才确认消费,正在运行突然强制关闭进程不会丢失一个消息,
下次启动还会消费或者被别的机器消费。
此框架的消息万无一失特性,不仅支持rabbbitmq因为原生支持,也支持redis,框架对redis的实现机制是因为客户端加了一层保障)。
定时:
可以按时间间隔、按指定时间执行一次、按指定时间执行多次,使用的是apscheduler包的方式。
延时任务:
例如规定任务发布后,延迟60秒执行,或者规定18点执行。这个概念和定时任务有一些不同。
指定时间不运行:
例如,有些任务你不想在白天运行,可以只在晚上的时间段运行
消费确认:
这是最为重要的一项功能之一,有了这才能肆无忌惮的任性反复重启代码也不会丢失一个任务。
(常规的手写 redis.lpush + redis.blpop,然后并发的运行取出来的消息,随意关闭重启代码瞬间会丢失大量任务,
那种有限的 断点接续 完全不可靠,根本不敢随意重启代码)
立即重试指定次数:
当函数运行出错,会立即重试指定的次数,达到最大次重试数后就确认消费了
重新入队:
在消费函数内部主动抛出一个特定类型的异常ExceptionForRequeue后,消息重新返回消息队列
超时杀死:
例如在函数运行时间超过10秒时候,将此运行中的函数kill
计算消费次数速度:
实时计算单个进程1分钟的消费次数,在日志中显示;当开启函数状态持久化后可在web页面查看消费次数
预估消费时间:
根据前1分钟的消费次数,按照队列剩余的消息数量来估算剩余的所需时间
函数运行日志记录:
使用自己设计开发的 控制台五彩日志(根据日志严重级别显示成五种颜色;使用了可跳转点击日志模板)
+ 多进程安全切片的文件日志 + 可选的kafka elastic日志
任务过滤:
例如求和的add函数,已经计算了1 + 2,再次发布1 + 2的任务到消息中间件,可以让框架跳过执行此任务。
任务过滤的原理是使用的是函数入参判断是否是已近执行过来进行过滤。
任务过滤有效期缓存:
例如查询深圳明天的天气,可以设置任务过滤缓存30分钟,30分钟内查询过深圳的天气,则不再查询。
30分钟以外无论是否查询过深圳明天的天气,则执行查询。
任务过期丢弃:
例如消息是15秒之前发布的,可以让框架丢弃此消息不执行,防止消息堆积,
在消息可靠性要求不高但实时性要求高的高并发互联网接口中使用
函数状态和结果持久化:
可以分别选择函数状态和函数结果持久化到mongodb,使用的是短时间内的离散mongo任务自动聚合成批量
任务后批量插入,尽可能的减少了插入次数
消费状态实时可视化:
在页面上按时间倒序实时刷新函数消费状态,包括是否成功 出错的异常类型和异常提示
重试运行次数 执行函数的机器名字+进程id+python脚本名字 函数入参 函数结果 函数运行消耗时间等
消费次数和速度生成统计表可视化:
生成echarts统计图,主要是统计最近60秒每秒的消费次数、最近60分钟每分钟的消费次数
最近24小时每小时的消费次数、最近10天每天的消费次数
rpc:
生产端(或叫发布端)获取消费结果。各个发布端对消费结果进行不同步骤的后续处理更灵活,而不是让消费端对消息的处理一干到底。
远程服务器部署消费函数:
代码里面 task_fun.fabric_deploy('192.168.6.133', 22, 'xiaomin', '123456', process_num=2) 只需要这样就可以自动将函数部署在远程机器运行,
无需任何额外操作,不需要借助阿里云codepipeline发版工具 和 任何运维发版管理工具,就能轻松将函数运行在多台远程机器。task_fun指的是被@boost装饰的函数
暂停消费:
支持从python解释器外部/远程机器 ,控制暂停消息消费和继续消费。
关于稳定性和性能,一句话概括就是直面百万c端用户(包括app和小程序), 已经连续超过三个季度稳定高效运行无事故,从没有出现过假死、崩溃、内存泄漏等问题。 windows和linux行为100%一致,不会像celery一样,相同代码前提下,很多功能在win上不能运行或出错。
1.3 框架使用例子
使用之前先学习 PYTHONPATH的概念 https://github.com/ydf0509/pythonpathdemo
win cmd和linux 运行时候,设置 PYTHONPATH 为项目根目录,是为了自动生成或读取到项目根目录下的 funboost_config.py文件作为配置。
以下这只是简单求和例子,实际情况换成任意函数里面写任意逻辑,框架可没有规定只能用于 求和函数 的自动调度并发。
而是根据实际情况函数的参数个数、函数的内部逻辑功能,全部都由用户自定义,函数里面想写什么就写什么,想干什么就干什么,极端自由。
也就是框架很容易学和使用,把下面的task_fun函数的入参和内部逻辑换成你自己想写的函数功能就可以了,框架只需要学习boost这一个函数的参数就行。
测试使用的时候函数里面加上sleep模拟阻塞,从而更好的了解框架的并发和各种控制功能。
有一点要说明的是框架的消息中间件的ip 端口 密码 等配置是在你第一次运行代码时候,在你当前项目的根目录下生成的 funboost_config.py 按需设置。
import time
from funboost import boost, BrokerEnum
@boost("task_queue_name1", qps=5, broker_kind=BrokerEnum.PERSISTQUEUE) # 入参包括20种,运行控制方式非常多,想得到的控制都会有。
def task_fun(x, y):
print(f'{x} + {y} = {x + y}')
time.sleep(3) # 框架会自动并发绕开这个阻塞,无论函数内部随机耗时多久都能自动调节并发达到每秒运行 5 次 这个 task_fun 函数的目的。
if __name__ == "__main__":
for i in range(100):
task_fun.push(i, y=i * 2) # 发布者发布任务
task_fun.consume() # 消费者启动循环调度并发消费任务"""
对于消费函数,框架内部会生成发布者(生产者)和消费者。
1.推送。 task_fun.push(1,y=2) 会把 {"x":1,"y":2} (消息也自动包含一些其他辅助信息) 发送到中间件的 task_queue_name1 队列中。
2.消费。 task_fun.consume() 开始自动从中间件拉取消息,并发的调度运行函数,task_fun(**{"x":1,"y":2}),每秒运行5次
整个过程只有这两步,清晰明了,其他的控制方式需要看 boost 的中文入参解释,全都参数都很有用。
这个是单个脚本实现了发布和消费,一般都是分离成两个文件的,任务发布和任务消费无需在同一个进程的解释器内部,
因为是使用了中间件解耦消息和持久化消息,不要被例子误导成了,以为发布和消费必须放在同一个脚本里面
框架使用方式基本上只需要练习这一个例子就行了,其他举得例子只是改了下broker_kind和其他参数而已,
而且装饰器的入参已近解释得非常详细了,框架浓缩到了一个装饰器,并没有用户需要从框架里面要继承什么组合什么的复杂写法。
用户可以修改此函数的sleep大小和@boost的数十种入参来学习 验证 测试框架的功能。
"""
1.4 python分布式函数执行为什么重要?
python比其他语言更需要分布式函数调度框架来执行函数,有两点原因
1 python有gil,
直接python xx.py启动没有包括multipricsessing的代码,在16核机器上,cpu最多只能达到100%,也就是最高使用率1/16,
别的语言直接启动代码最高cpu可以达到1600%。如果在python代码里面亲自写多进程将会十分麻烦,对代码需要改造需要很大
,多进程之间的通讯,多进程之间的任务共享、任务分配,将会需要耗费大量额外代码,
而分布式行函数调度框架天生使用中间件解耦的来存储任务,使得单进程的脚本和多进程在写法上
没有任何区别都不需要亲自导入multiprocessing包,也不需要手动分配任务给每个进程和搞进程间通信,
因为每个任务都是从中间件里面获取来的。
2 python性能很差,不光是gil问题,只要是动态语言无论是否有gil限制,都比静态语言慢很多。
那么就不光是需要跨进程执行任务了,例如跨pvm解释器启动脚本共享任务(即使是同一个机器,把python xx.py连续启动多次)、
跨docker容器、跨物理机共享任务。只有让python跑在更多进程的cpu核心 跑在更多的docker容器 跑在更多的物理机上,
python才能获得与其他语言只需要一台机器就实现的执行速度。分布式函数调度框架来驱动函数执行针对这些不同的场景,
用户代码不需要做任何变化。
所以比其他语言来说,python是更需要分布式函数调度框架来执行任务。
1.5 框架学习方式
把1.3的求和例子,通过修改boost装饰器额参数和sleep大小反复测试两数求和,
从而体会框架的分布式 并发 控频。
这是最简单的框架,只有@boost 1行代码需要学习。说的是这是最简单框架,这不是最简单的python包。
如果连只有一个重要函数的框架都学不会,那就学不会学习得了更复杂的其他框架了,大部分框架都很复杂比学习一个包难很多。
大部分框架,都要深入使用里面的很多个类,还需要继承组合一顿。