guillaume-chevalier / Glove As A Tensorflow Embedding Layer
Projects that are alternatives of or similar to Glove As A Tensorflow Embedding Layer
GloVe as a TensorFlow Embedding layer
In this tutorial, we'll see how to convert GloVe embeddings to TensorFlow layers. This could also work with embeddings generated from word2vec.
First, we'll download the embedding we need.
Second, we'll load it into TensorFlow to convert input words with the embedding to word features. The conversion is done within TensorFlow, so it is GPU-optimized and it could run on batches on the GPU. It is also possible to run this tutorial with just a CPU. We'll play with word representations once the embedding is loaded.
What you'll need:
- A working installation of TensorFlow.
- 4 to 6 GB of disk space to download embeddings.
First, some theory
Representations
We need a way to represent content in neural networks. For audio, it's possible to use a spectrogram. For images, it's possible to directly use the pixels and then get features maps from a convolutional neural network. For text, analyzing every letter is costly, so it's better to use word representations to embed words or documents as vectors into Artificial Neural Networks and other Machine Learning algorithms.

As described by Keras, an embedding:
"Turns positive integers (indexes) into dense vectors of fixed size".
That's it. It's to extract features from words. An embedding is a huge matrix for which each row is a word, and each column is a feature from that word. To summarize, it's possible to convert a word to a vector of a certain length, such as 25, or 100, 200, 1000, and on. In practice, a length of 100 to 300 features is acceptable. With less than 100, we would risk underfitting our linguistic dataset. Word embeddings can eat a lot of RAM, so in this tutorial we'll download and use dimensions of size 25, however changing that to 200 would be a breeze with the actual code.
You can compute word analogies
The word representations (features) are linear, therefore it's possible to add and substract words with word embeddings. For example, here's the most known word analogy example:
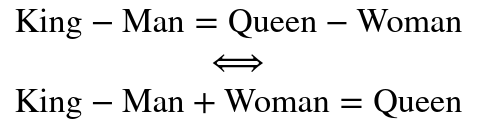
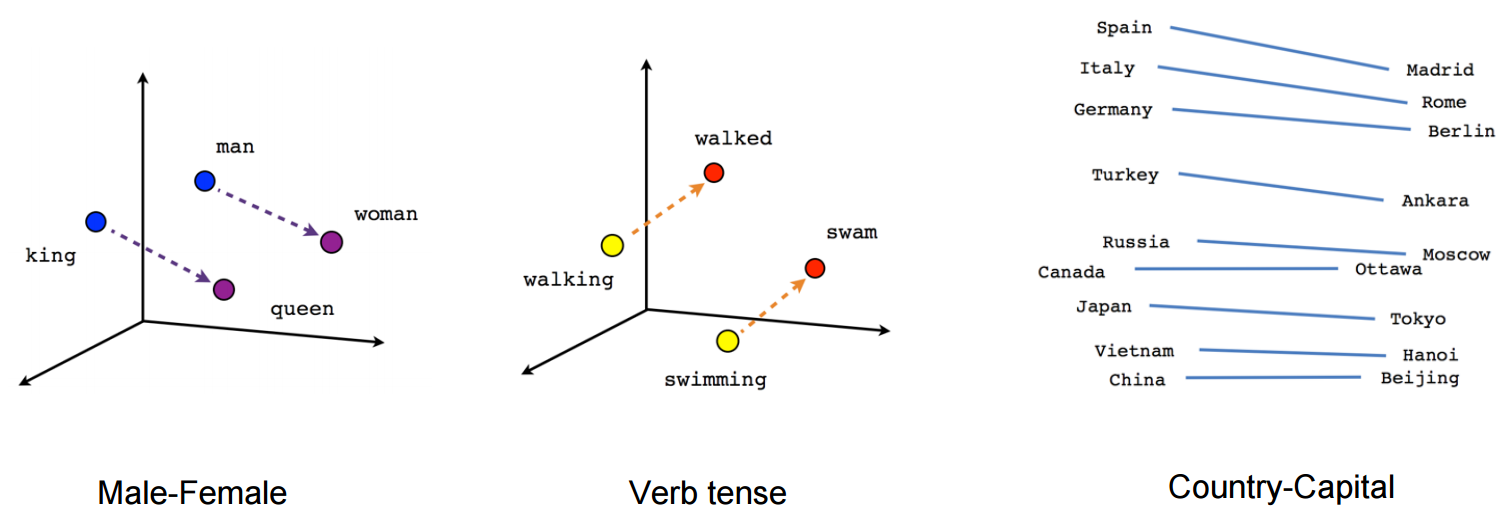
For example, it's possible to change from:
- Masculine and feminine
- Country and capital
- Singular and plural
- Verb tenses
- And the list goes on...
It's also possible to compute the Cosine Similarity between a word A and a word B, which is the cosine of the angle between the two words. A cosine similarity of -1 would mean the words are complete opposites, while a cosine similarity of 1 would mean that the words are the same. Here's the formula to compare two words:
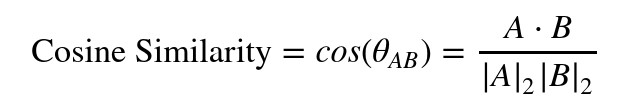
Here, the norm (such as |A|₂) is the L2 norm, the radius in space from the origin, but in a higher dimensional space such as with $n=300$:
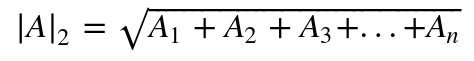
How does it looks like concretely?
For example, here are some cosine similarities to the word "king", computed from the code explained below:
| Other Word | Cosine Similarity |
|---|---|
| prince: | 0.933741, |
| queen: | 0.9202421, |
| aka: | 0.91769224, |
| lady: | 0.9163239, |
| jack: | 0.91473544, |
| 's: | 0.90668976, |
| stone: | 0.8982374, |
| mr.: | 0.89194083, |
| the: | 0.88934386, |
| star: | 0.88920873, |
Finally, notice how similar words are close in space:
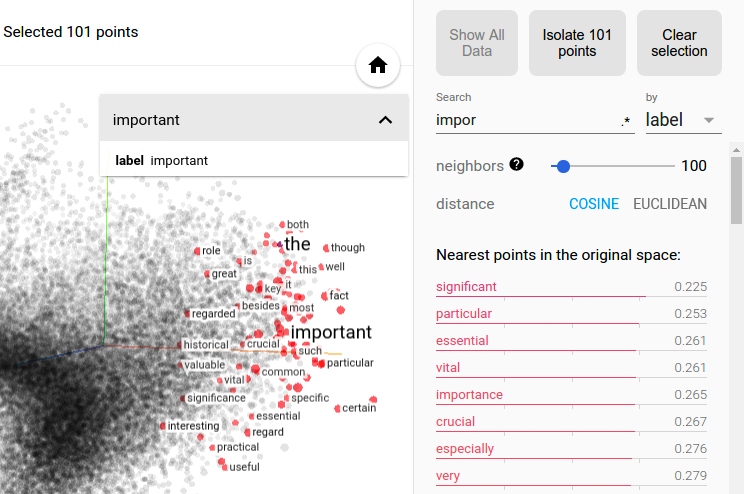
Note: in the image above, the embedding have been subsampled to a lower 3D space with a PCA (Princial Component Analysis) or t-SNE (t-distributed Stochastic Neighbor Embedding) to be explorable. This is possible with TensorBoard for inspection. 300 dimensions can't be visualised easily.
But how are those word representations obtained?
Before continuing to the practical part where we'll use pretrained embeddings, it's a good thing to know that embeddings can be obtained from unsupervised training on large datasets of text. That's at least a way we can use the text off the internet! To perform this training to get an embedding, it's possible to go with the word2vec approach, or also with the GloVe (Global word Vectors). GloVe is a more recent approach that builds upon the theory of word2vec. Here, we'll use GloVe embeddings. To summarize how the unsupervised training happens, let's see what John Rupert Firth has to say:
You shall know a word by the company it keeps (Firth, J. R., 1957)
It's amazing that by comparing words and trying to guess the surrounding words, it's possible to find their meaning. To learn more on that, I'd recommend you the 5th course of the Deep Learning Specialization on coursera by Andrew Ng, a course which can lead to the Deep Learning Specialization certificate.
Let's get practical!
First, download the pretrained embeddings with the code below
Careful, the download will take 4-6 GB on disks. If you have already downloaded the embeddings, they will be located under the ./embeddings/ folder relative to here, and won't be downloaded again.
Note: several embeddings were downloaded with different dimension sizes in the zip file, but we only need one.
import numpy as np
import tensorflow as tf
import chakin
import json
import os
from collections import defaultdict
chakin.search(lang='English')
Name Dimension Corpus VocabularySize \
2 fastText(en) 300 Wikipedia 2.5M
11 GloVe.6B.50d 50 Wikipedia+Gigaword 5 (6B) 400K
12 GloVe.6B.100d 100 Wikipedia+Gigaword 5 (6B) 400K
13 GloVe.6B.200d 200 Wikipedia+Gigaword 5 (6B) 400K
14 GloVe.6B.300d 300 Wikipedia+Gigaword 5 (6B) 400K
15 GloVe.42B.300d 300 Common Crawl(42B) 1.9M
16 GloVe.840B.300d 300 Common Crawl(840B) 2.2M
17 GloVe.Twitter.25d 25 Twitter(27B) 1.2M
18 GloVe.Twitter.50d 50 Twitter(27B) 1.2M
19 GloVe.Twitter.100d 100 Twitter(27B) 1.2M
20 GloVe.Twitter.200d 200 Twitter(27B) 1.2M
21 word2vec.GoogleNews 300 Google News(100B) 3.0M
Method Language Author
2 fastText English Facebook
11 GloVe English Stanford
12 GloVe English Stanford
13 GloVe English Stanford
14 GloVe English Stanford
15 GloVe English Stanford
16 GloVe English Stanford
17 GloVe English Stanford
18 GloVe English Stanford
19 GloVe English Stanford
20 GloVe English Stanford
21 word2vec English Google
# Downloading Twitter.25d embeddings from Stanford:
CHAKIN_INDEX = 17
NUMBER_OF_DIMENSIONS = 25
SUBFOLDER_NAME = "glove.twitter.27B"
DATA_FOLDER = "embeddings"
ZIP_FILE = os.path.join(DATA_FOLDER, "{}.zip".format(SUBFOLDER_NAME))
ZIP_FILE_ALT = "glove" + ZIP_FILE[5:] # sometimes it's lowercase only...
UNZIP_FOLDER = os.path.join(DATA_FOLDER, SUBFOLDER_NAME)
if SUBFOLDER_NAME[-1] == "d":
GLOVE_FILENAME = os.path.join(UNZIP_FOLDER, "{}.txt".format(SUBFOLDER_NAME))
else:
GLOVE_FILENAME = os.path.join(UNZIP_FOLDER, "{}.{}d.txt".format(SUBFOLDER_NAME, NUMBER_OF_DIMENSIONS))
if not os.path.exists(ZIP_FILE) and not os.path.exists(UNZIP_FOLDER):
# GloVe by Stanford is licensed Apache 2.0:
# https://github.com/stanfordnlp/GloVe/blob/master/LICENSE
# http://nlp.stanford.edu/data/glove.twitter.27B.zip
# Copyright 2014 The Board of Trustees of The Leland Stanford Junior University
print("Downloading embeddings to '{}'".format(ZIP_FILE))
chakin.download(number=CHAKIN_INDEX, save_dir='./{}'.format(DATA_FOLDER))
else:
print("Embeddings already downloaded.")
if not os.path.exists(UNZIP_FOLDER):
import zipfile
if not os.path.exists(ZIP_FILE) and os.path.exists(ZIP_FILE_ALT):
ZIP_FILE = ZIP_FILE_ALT
with zipfile.ZipFile(ZIP_FILE,"r") as zip_ref:
print("Extracting embeddings to '{}'".format(UNZIP_FOLDER))
zip_ref.extractall(UNZIP_FOLDER)
else:
print("Embeddings already extracted.")
Embeddings already downloaded.
Embeddings already extracted.
Let's read the embedding from disks here
First, we load the embeddings, then we demonstrate their usage.
def load_embedding_from_disks(glove_filename, with_indexes=True):
"""
Read a GloVe txt file. If `with_indexes=True`, we return a tuple of two dictionnaries
`(word_to_index_dict, index_to_embedding_array)`, otherwise we return only a direct
`word_to_embedding_dict` dictionnary mapping from a string to a numpy array.
"""
if with_indexes:
word_to_index_dict = dict()
index_to_embedding_array = []
else:
word_to_embedding_dict = dict()
with open(glove_filename, 'r') as glove_file:
for (i, line) in enumerate(glove_file):
split = line.split(' ')
word = split[0]
representation = split[1:]
representation = np.array(
[float(val) for val in representation]
)
if with_indexes:
word_to_index_dict[word] = i
index_to_embedding_array.append(representation)
else:
word_to_embedding_dict[word] = representation
_WORD_NOT_FOUND = [0.0]* len(representation) # Empty representation for unknown words.
if with_indexes:
_LAST_INDEX = i + 1
word_to_index_dict = defaultdict(lambda: _LAST_INDEX, word_to_index_dict)
index_to_embedding_array = np.array(index_to_embedding_array + [_WORD_NOT_FOUND])
return word_to_index_dict, index_to_embedding_array
else:
word_to_embedding_dict = defaultdict(lambda: _WORD_NOT_FOUND)
return word_to_embedding_dict
print("Loading embedding from disks...")
word_to_index, index_to_embedding = load_embedding_from_disks(GLOVE_FILENAME, with_indexes=True)
print("Embedding loaded from disks.")
Loading embedding from disks...
Embedding loaded from disks.
Unknown words have representations with values of zero, such as [0, 0, ..., 0]
vocab_size, embedding_dim = index_to_embedding.shape
print("Embedding is of shape: {}".format(index_to_embedding.shape))
print("This means (number of words, number of dimensions per word)\n")
print("The first words are words that tend occur more often.")
print("Note: for unknown words, the representation is an empty vector,\n"
"and the index is the last one. The dictionnary has a limit:")
print(" {} --> {} --> {}".format("A word", "Index in embedding", "Representation"))
word = "worsdfkljsdf"
idx = word_to_index[word]
embd = list(np.array(index_to_embedding[idx], dtype=int)) # "int" for compact print only.
print(" {} --> {} --> {}".format(word, idx, embd))
word = "the"
idx = word_to_index[word]
embd = list(index_to_embedding[idx]) # "int" for compact print only.
print(" {} --> {} --> {}".format(word, idx, embd))
Embedding is of shape: (1193515, 25)
This means (number of words, number of dimensions per word)
The first words are words that tend occur more often.
Note: for unknown words, the representation is an empty vector,
and the index is the last one. The dictionnary has a limit:
A word --> Index in embedding --> Representation
worsdfkljsdf --> 1193514 --> [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
the --> 13 --> [-0.010167, 0.020194, 0.21473, 0.17289, -0.43659, -0.14687, 1.8429, -0.15753, 0.18187, -0.31782, 0.06839, 0.51776, -6.3371, 0.48066, 0.13777, -0.48568, 0.39, -0.0019506, -0.10218, 0.21262, -0.86146, 0.17263, 0.18783, -0.8425, -0.31208]
The L2 norm of some words can vary
Notice how more common words have a longer embedding norm, how some text on Twitter was in French, and how it deals with punctuation
words = [
"The", "Teh", "A", "It", "Its", "Bacon", "Star", "Clone", "Bonjour", "Intelligence",
"À", "A", "Ça", "Ca", "Été", "C'est", "Aujourd'hui", "Aujourd", "'", "hui", "?", "!", ",", ".", "-", "/", "~"
]
for word in words:
word_ = word.lower()
embedding = index_to_embedding[word_to_index[word_]]
norm = str(np.linalg.norm(embedding))
print((word + ": ").ljust(15) + norm)
print("Note: here we printed words starting with capital letters, \n"
"however to take their embeddings we need their lowercase version (str.lower())")
The: 6.825211375610675
Teh: 5.168743789022242
A: 6.697466132368121
It: 6.6026557827711265
Its: 5.815954107190023
Bacon: 5.061203156401844
Star: 4.377212317550177
Clone: 3.318821469851497
Bonjour: 4.569226609068979
Intelligence: 4.978693160848336
À: 6.757003390719884
A: 6.697466132368121
Ça: 6.447278498352788
Ca: 5.757383694621195
Été: 5.7824019165330425
C'est: 6.6648048720694
Aujourd'hui: 0.0
Aujourd: 5.28318283424017
': 5.146860627039459
hui: 4.813765207599868
?: 5.291857611164723
!: 5.145156971946508
,: 5.401075354278071
.: 4.965766197438418
-: 5.10790151248338
/: 5.063642432429447
~: 4.910993053437055
Note: here we printed words starting with capital letters,
however to take their embeddings we need their lowercase version (str.lower())
Let's load the embedding in TensorFlow
We simply create a non-trainable (frozen) tf.Variable() which we set to hold the value of the big embedding matrix.
First, let's define the variables and graph:
batch_size = None # Any size is accepted
tf.reset_default_graph()
sess = tf.InteractiveSession() # sess = tf.Session()
# Define the variable that will hold the embedding:
tf_embedding = tf.Variable(
tf.constant(0.0, shape=index_to_embedding.shape),
trainable=False,
name="Embedding"
)
tf_word_ids = tf.placeholder(tf.int32, shape=[batch_size])
tf_word_representation_layer = tf.nn.embedding_lookup(
params=tf_embedding,
ids=tf_word_ids
)
Sending the embedding to TensorFlow below. It will be located in the GPU from now (or on CPU if GPU is unavailable):
tf_embedding_placeholder = tf.placeholder(tf.float32, shape=index_to_embedding.shape)
tf_embedding_init = tf_embedding.assign(tf_embedding_placeholder)
_ = sess.run(
tf_embedding_init,
feed_dict={
tf_embedding_placeholder: index_to_embedding
}
)
print("Embedding now stored in TensorFlow. Can delete numpy array to clear some CPU RAM.")
del index_to_embedding
Embedding now stored in TensorFlow. Can delete numpy array to clear some CPU RAM.
Now we can use or fetch representations, for example:
batch_of_words = ["Hello", "World", "!"]
batch_indexes = [word_to_index[w.lower()] for w in batch_of_words]
embedding_from_batch_lookup = sess.run(
tf_word_representation_layer,
feed_dict={
tf_word_ids: batch_indexes
}
)
print("Representations for {}:".format(batch_of_words))
print(embedding_from_batch_lookup)
Representations for ['Hello', 'World', '!']:
[[-0.77069 0.12827 0.33137 0.0050893 -0.47605 -0.50116
1.858 1.0624 -0.56511 0.13328 -0.41918 -0.14195
-2.8555 -0.57131 -0.13418 -0.44922 0.48591 -0.6479
-0.84238 0.61669 -0.19824 -0.57967 -0.65885 0.43928
-0.50473 ]
[ 0.10301 0.095666 -0.14789 -0.22383 -0.14775 -0.11599
1.8513 0.24886 -0.41877 -0.20384 -0.08509 0.33246
-4.6946 0.84096 -0.46666 -0.031128 -0.19539 -0.037349
0.58949 0.13941 -0.57667 -0.44426 -0.43085 -0.52875
0.25855 ]
[ 0.4049 -0.87651 -0.23362 -0.34844 -0.097002 0.40895
1.6928 1.7058 -1.293 0.70091 -0.12498 -0.75998
-3.1586 0.14081 0.57255 -0.46097 -0.75721 -0.72414
-1.4071 -0.17224 0.0099324 -0.45711 0.074886 1.2035
1.1614 ]]
To avoid loading the embedding twice in RAM, make TensorFlow able to load them from disks directly
prefix = SUBFOLDER_NAME + "." + str(NUMBER_OF_DIMENSIONS) + "d"
TF_EMBEDDINGS_FILE_NAME = os.path.join(DATA_FOLDER, prefix + ".ckpt")
DICT_WORD_TO_INDEX_FILE_NAME = os.path.join(DATA_FOLDER, prefix + ".json")
variables_to_save = [tf_embedding]
embedding_saver = tf.train.Saver(variables_to_save)
embedding_saver.save(sess, save_path=TF_EMBEDDINGS_FILE_NAME)
print("TF embeddings saved to '{}'.".format(TF_EMBEDDINGS_FILE_NAME))
sess.close()
with open(DICT_WORD_TO_INDEX_FILE_NAME, 'w') as f:
json.dump(word_to_index, f)
print("word_to_index dict saved to '{}'.".format(DICT_WORD_TO_INDEX_FILE_NAME))
TF embeddings saved to 'embeddings/glove.twitter.27B.25d.ckpt'.
word_to_index dict saved to 'embeddings/glove.twitter.27B.25d.json'.
words_B = "like absolutely crazy not hate bag sand rock soap"
r = [word_to_index[w.strip()] for w in words_B]
print(words_B)
print(r)
like absolutely crazy not hate bag sand rock soap
[293, 10, 151, 49, 1193514, 11, 76, 137, 50, 293, 51, 187, 49, 293, 47, 1193514, 210, 73, 11, 1016, 47, 1193514, 36, 50, 187, 1193514, 369, 11, 187, 49, 1193514, 76, 11, 456, 1193514, 137, 11, 36, 199, 1193514, 73, 50, 210, 151, 1193514, 137, 50, 11, 351]
Build a model to get word similarities from word A to a list of many words B
This is for demo purposes. With a GPU, we can fetch many words quickly and compute on them.
Restarting from scratch: resetting the Jupyter notebook and loading embeddings from disks, the good way
Now that we have a TensorFlow checkpoint, let's load the embedding without having to parse the txt file into NumPy in CPU:
# Magic iPython/Jupyter command to delete variables and restart the Python kernel
%reset
Once deleted, variables cannot be recovered. Proceed (y/[n])? y
import numpy as np
import tensorflow as tf
import os
import json
from string import punctuation
from collections import defaultdict
batch_size = None # Any size is accepted
word_representations_dimensions = 25 # Embedding of size (vocab_len, nb_dimensions)
DATA_FOLDER = "embeddings"
SUBFOLDER_NAME = "glove.twitter.27B"
TF_EMBEDDING_FILE_NAME = "{}.ckpt".format(SUBFOLDER_NAME)
SUFFIX = SUBFOLDER_NAME + "." + str(word_representations_dimensions)
TF_EMBEDDINGS_FILE_PATH = os.path.join(DATA_FOLDER, SUFFIX + "d.ckpt")
DICT_WORD_TO_INDEX_FILE_NAME = os.path.join(DATA_FOLDER, SUFFIX + "d.json")
def load_word_to_index(dict_word_to_index_file_name):
"""
Load a `word_to_index` dict mapping words to their id, with a default value
of pointing to the last index when not found, which is the unknown word.
"""
with open(dict_word_to_index_file_name, 'r') as f:
word_to_index = json.load(f)
_LAST_INDEX = len(word_to_index) - 2 # Why - 2? Open issue?
print("word_to_index dict restored from '{}'.".format(dict_word_to_index_file_name))
word_to_index = defaultdict(lambda: _LAST_INDEX, word_to_index)
return word_to_index
def load_embedding_tf(word_to_index, tf_embeddings_file_path, nb_dims):
"""
Define the embedding tf.Variable and load it.
"""
# 1. Define the variable that will hold the embedding:
tf_embedding = tf.Variable(
tf.constant(0.0, shape=[len(word_to_index)-1, nb_dims]),
trainable=False,
name="Embedding"
)
# 2. Restore the embedding from disks to TensorFlow, GPU (or CPU if GPU unavailable):
variables_to_restore = [tf_embedding]
embedding_saver = tf.train.Saver(variables_to_restore)
embedding_saver.restore(sess, save_path=tf_embeddings_file_path)
print("TF embeddings restored from '{}'.".format(tf_embeddings_file_path))
return tf_embedding
def cosine_similarity_tensorflow(tf_word_representation_A, tf_words_representation_B):
"""
Returns the `cosine_similarity = cos(angle_between_a_and_b_in_space)`
for the two word A to all the words B.
The first input word must be a 1D Tensors (word_representation).
The second input words must be 2D Tensors (batch_size, word_representation).
The result is a tf tensor that must be fetched with `sess.run`.
"""
a_normalized = tf.nn.l2_normalize(tf_word_representation_A, axis=-1)
b_normalized = tf.nn.l2_normalize(tf_words_representation_B, axis=-1)
similarity = tf.reduce_sum(
tf.multiply(a_normalized, b_normalized),
axis=-1
)
return similarity
# In case you didn't do the "%reset":
tf.reset_default_graph()
sess = tf.InteractiveSession() # sess = tf.Session()
# Load the embedding matrix in tf
word_to_index = load_word_to_index(
DICT_WORD_TO_INDEX_FILE_NAME)
tf_embedding = load_embedding_tf(
word_to_index,
TF_EMBEDDINGS_FILE_PATH,
word_representations_dimensions)
# Input to the graph where word IDs can be sent in batch. Look at the "shape" args:
tf_word_A_id = tf.placeholder(tf.int32, shape=[1])
tf_words_B_ids = tf.placeholder(tf.int32, shape=[batch_size])
# Conversion of words to a representation
tf_word_representation_A = tf.nn.embedding_lookup(
params=tf_embedding, ids=tf_word_A_id)
tf_words_representation_B = tf.nn.embedding_lookup(
params=tf_embedding, ids=tf_words_B_ids)
# The graph output are the "cosine_similarities" which we want to fetch in sess.run(...).
cosine_similarities = cosine_similarity_tensorflow(
tf_word_representation_A,
tf_words_representation_B)
print("Model created.")
word_to_index dict restored from 'embeddings/glove.twitter.27B.25d.json'.
INFO:tensorflow:Restoring parameters from embeddings/glove.twitter.27B.25d.ckpt
TF embeddings restored from 'embeddings/glove.twitter.27B.25d.ckpt'.
Model created.
Testing the fetch:
def sentence_to_word_ids(sentence, word_to_index):
"""
Note: there might be a better way to split sentences for GloVe.
Please look at the documentation or open an issue to suggest a fix.
"""
# Separating punctuation from words:
for punctuation_character in punctuation:
sentence = sentence.replace(punctuation_character, " {} ".format(punctuation_character))
# Removing double spaces and lowercasing:
sentence = sentence.replace(" ", " ").replace(" ", " ").lower().strip()
# Splitting on every space:
split_sentence = sentence.split(" ")
# Converting to IDs:
ids = [word_to_index[w.strip()] for w in split_sentence]
return ids, split_sentence
def predict_cosine_similarities(sess, word_A, words_B):
"""
Use the model in sess to predict cosine similarities.
"""
word_A_id, _ = sentence_to_word_ids(word_A, word_to_index)
words_B_ids, split_sentence = sentence_to_word_ids(words_B, word_to_index)
evaluated_cos_similarities = sess.run(
cosine_similarities,
feed_dict={
tf_word_A_id: word_A_id,
tf_words_B_ids: words_B_ids
}
)
return evaluated_cos_similarities, split_sentence
word_A = "Science"
words_B = "Hello internet, a vocano erupt like the bitcoin out of the blue and there is an unknownWord00!"
evaluated_cos_similarities, splitted = predict_cosine_similarities(sess, word_A, words_B)
print("Cosine similarities with \"{}\":".format(word_A))
for word, similarity in zip(splitted, evaluated_cos_similarities):
print(" {}{}".format((word+":").ljust(15), similarity))
Cosine similarities with "Science":
hello: 0.4928313195705414
internet: 0.6569848656654358
,: 0.49928268790245056
a: 0.4862615764141083
vocano: 0.0
erupt: 0.16974501311779022
like: 0.6019276976585388
the: 0.7420801520347595
bitcoin: 0.5125284194946289
out: 0.6307196617126465
of: 0.7674074172973633
the: 0.7420801520347595
blue: 0.4629560112953186
and: 0.6889371275901794
there: 0.7172714471817017
is: 0.7015751600265503
an: 0.6883363723754883
unknownword00: 0.0
!: 0.3991800844669342
Getting the top k most similars words to a word with the embedding matrix
Let's take an input word and compare it to every other words in the embedding matrix to return the most similar words.
tf.reset_default_graph()
# Transpose word_to_index dict:
index_to_word = dict((val, key) for key, val in word_to_index.items())
# New graph
tf.reset_default_graph()
sess = tf.InteractiveSession()
# Load the embedding matrix in tf
tf_word_to_index = load_word_to_index(
DICT_WORD_TO_INDEX_FILE_NAME)
tf_embedding = load_embedding_tf(
tf_word_to_index,
TF_EMBEDDINGS_FILE_PATH,
word_representations_dimensions)
# An input word
tf_word_id = tf.placeholder(tf.int32, shape=[1])
tf_word_representation = tf.nn.embedding_lookup(
params=tf_embedding, ids=tf_word_id)
# An input
tf_nb_similar_words_to_get = tf.placeholder(tf.int32)
# Dot the word to every embedding
tf_all_cosine_similarities = cosine_similarity_tensorflow(
tf_word_representation,
tf_embedding)
# Getting the top cosine similarities.
tf_top_cosine_similarities, tf_top_word_indices = tf.nn.top_k(
tf_all_cosine_similarities,
k=tf_nb_similar_words_to_get+1,
sorted=True
)
# Discard the first word because it's the input word itself:
tf_top_cosine_similarities = tf_top_cosine_similarities[1:]
tf_top_word_indices = tf_top_word_indices[1:]
# Get the top words' representations by fetching
# tf_top_words_representation = "tf_embedding[tf_top_word_indices]":
tf_top_words_representation = tf.gather(
tf_embedding,
tf_top_word_indices)
word_to_index dict restored from 'embeddings/glove.twitter.27B.25d.json'.
INFO:tensorflow:Restoring parameters from embeddings/glove.twitter.27B.25d.ckpt
TF embeddings restored from 'embeddings/glove.twitter.27B.25d.ckpt'.
# Fetch 10 similar words:
nb_similar_words_to_get = 10
word = "king"
word_id = word_to_index[word]
top_cosine_similarities, top_word_indices, top_words_representation = sess.run(
[tf_top_cosine_similarities, tf_top_word_indices, tf_top_words_representation],
feed_dict={
tf_word_id: [word_id],
tf_nb_similar_words_to_get: nb_similar_words_to_get
}
)
print("Top similar words to \"{}\":\n".format(word))
loop = zip(top_cosine_similarities, top_word_indices, top_words_representation)
for cos_sim, word_id, word_repr in loop:
print(
(index_to_word[word_id]+ ":").ljust(15),
(str(cos_sim) + ",").ljust(15),
np.linalg.norm(word_repr)
)
Top similar words to "king":
prince: 0.933741, 4.1957383
queen: 0.9202421, 4.1540723
aka: 0.91769224, 3.5418782
lady: 0.9163239, 4.256068
jack: 0.91473544, 4.2670665
's: 0.90668976, 6.276691
stone: 0.8982374, 4.2092624
mr.: 0.89194083, 4.1567283
the: 0.88934386, 6.8252115
star: 0.88920873, 4.3772125
Notice the bad quality of the similar words, embeddings with more dimensions than 25 would make it better.
Reminder: we chose 25 dimensions for tutorial purposes not to eat all our RAM. There are better embeddings out there.
What's next?
I think getting the embeddings into TensorFlow is a good step into building a language model. You may want to grab some data, such as here and here. You may also want to learn more about how recurrent neural networks can read features such as sentences or signal of varying length, such as an LSTM (RNN) encoder reading signal or an signal predictor from a seq2seq GRU (RNN) which could be used in practice to predict next words in a sentence. Since signal is closely related to sentences with embedded words, RNNs can be applied on both.
References
The pretrained word vectors can be found there:
- Repo https://github.com/stanfordnlp/GloVe
- Manual download: http://nlp.stanford.edu/data/glove.twitter.27B.zip
Chakin was used to download those word embeddings:
Some images in this notebook are references/links from the TensorFlow website:
To cite my work, point to the URL of the GitHub repository:
My code is available under the MIT License.
Connect with me
- https://ca.linkedin.com/in/chevalierg
- https://twitter.com/guillaume_che
- https://github.com/guillaume-chevalier/
# Let's convert this notebook to a README for the GitHub project's title page:
!ipython3 nbconvert --to markdown "GloVe-as-TensorFlow-Embedding-Tutorial.ipynb"
!mv "GloVe-as-TensorFlow-Embedding-Tutorial.md" README.md
[TerminalIPythonApp] WARNING | Subcommand `ipython nbconvert` is deprecated and will be removed in future versions.
[TerminalIPythonApp] WARNING | You likely want to use `jupyter nbconvert` in the future
[NbConvertApp] Converting notebook GloVe-as-TensorFlow-Embedding-Tutorial.ipynb to markdown
[NbConvertApp] Writing 30873 bytes to GloVe-as-TensorFlow-Embedding-Tutorial.md