Project Overview
This is a Udacity capstone project which aims to test the feasibility of CNNs for Japanese OCR, on mobile devices.
Feature map pruning is used to reduce the size of the model & increase inference speed. (follow the approach in [5])
Refer to capestone_report.pdf for a complete description of the project.
Benchmark Summary:
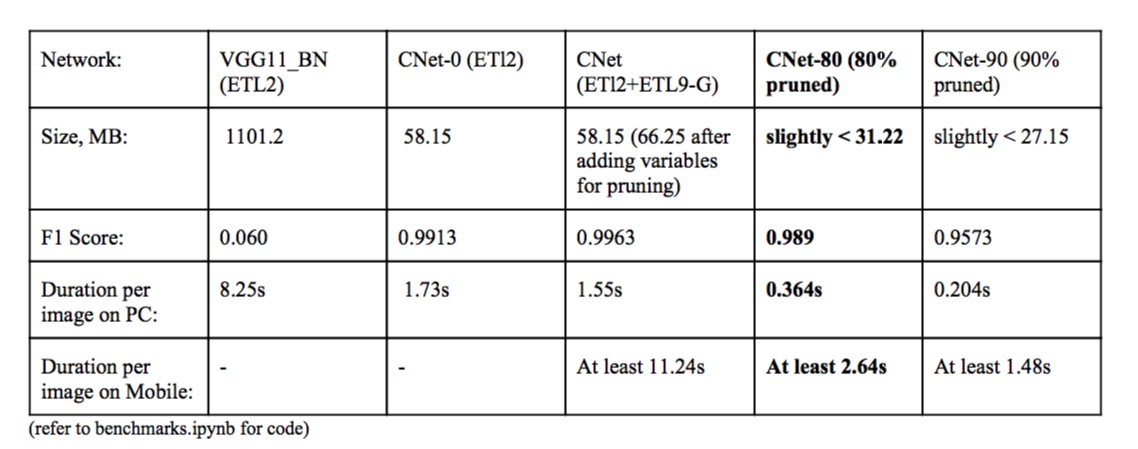 Note: size estimate is the raw size estimate for models in Pytorch, inclusive of layer specific details like output count. Sizes are about halved if only the filters in convolutional & FC layers are considered.
Note: size estimate is the raw size estimate for models in Pytorch, inclusive of layer specific details like output count. Sizes are about halved if only the filters in convolutional & FC layers are considered.
Running this project
Python version: 3.6.3
Required packages:
- pipy's bitstring
- numpy
- tqdm
- [email protected] with gpu support, (was built from source. 0.3 may work, untested)
- torchvision
- sklearn
Optional:
(code related to exporting to mobile has been commented out)
- onnx
- caffe2
- onnx-caffe2
Note that the pytorch code uses cuda for training models.
Training with CPU has not been tested, but code should support it.
Setup instructions
Obtain the ETL2 & ETL9G datasets from the following sites.
You will need to create an account to get the files.
https://etlcdb.db.aist.go.jp/?page_id=1721
https://etlcdb.db.aist.go.jp/?page_id=1721
Please insert the downloaded files in raw_data directory, the result should look like this
. (raw_data)
├── ETL2
│ ├── ETL2INFO
│ ├── ETL2_1
│ ├── ETL2_2
│ ├── ...
│ └── ETL2_5
├── ETL9G
│ ├── ETL9G_01
│ ├── ETL9G_02
│ ├── ...
│ └── ETL9G_50
├── README.md
└── co59-utf8.txt
Running
To train the models, run the following code at root:
python -m src.main --train --model MODEL_NAME --dataset DATASET_NAME
MODEL_NAMES:
vgg11_bn
chinese_net
DATASET_NAMES:
etl2
etl2_9g
References
This work was made possible by the following papers:
[1] Zhang, X., Bengio, Y., & Liu, C. (2016, June 18). Online and Offline Handwritten Chinese Character Recognition: A Comprehensive Study and New Benchmark. Retrieved December 10, 2017, from https://arxiv.org/abs/1606.05763
[2] Xiao, X., Jin, L., Yang, Y., Yang, W., Sun, J., & Chang, T. (2017, February 26). Building Fast and Compact Convolutional Neural Networks for Offline Handwritten Chinese Character Recognition. Retrieved December 10, 2017, from https://arxiv.org/abs/1702.07975
[3] Wojna, Z., Gorban, A., Lee, D., Murphy, K., Yu, Q., Li, Y., & Ibarz, J. (2017, August 20). Attention-based Extraction of Structured Information from Street View Imagery. Retrieved December 10, 2017, from https://arxiv.org/abs/1704.03549
[4] Tsai, C. Recognizing Handwritten Japanese Characters Using Deep Convolutional Neural Networks Retrieved December 10, 2017, from https://cs231n.stanford.edu/reports/2016/pdfs/262_Report.pdf
[5] Molchanov, P., Tyree, S., Karras, T., Aila, T., & Kautz, J. (2017, June 08). Pruning Convolutional Neural Networks for Resource Efficient Inference. Retrieved December 10, 2017, from https://arxiv.org/abs/1611.06440