RandolphVI / Multi Label Text Classification
Programming Languages
Projects that are alternatives of or similar to Multi Label Text Classification
Deep Learning for Multi-Label Text Classification
![]()



This repository is my research project, and it is also a study of TensorFlow, Deep Learning (Fasttext, CNN, LSTM, etc.).
The main objective of the project is to solve the multi-label text classification problem based on Deep Neural Networks. Thus, the format of the data label is like [0, 1, 0, ..., 1, 1] according to the characteristics of such a problem.
Requirements
- Python 3.6
- Tensorflow 1.15.0
- Tensorboard 1.15.0
- Sklearn 0.19.1
- Numpy 1.16.2
- Gensim 3.8.3
- Tqdm 4.49.0
Project
The project structure is below:
.
├── Model
│ ├── test_model.py
│ ├── text_model.py
│ └── train_model.py
├── data
│ ├── word2vec_100.model.* [Need Download]
│ ├── Test_sample.json
│ ├── Train_sample.json
│ └── Validation_sample.json
└── utils
│ ├── checkmate.py
│ ├── data_helpers.py
│ └── param_parser.py
├── LICENSE
├── README.md
└── requirements.txt
Innovation
Data part
- Make the data support Chinese and English (Can use
jiebaornltk). - Can use your pre-trained word vectors (Can use
gensim). - Add embedding visualization based on the tensorboard (Need to create
metadata.tsvfirst).
Model part
- Add the correct L2 loss calculation operation.
- Add gradients clip operation to prevent gradient explosion.
- Add learning rate decay with exponential decay.
- Add a new Highway Layer (Which is useful according to the model performance).
- Add Batch Normalization Layer.
Code part
- Can choose to train the model directly or restore the model from the checkpoint in
train.py. - Can predict the labels via threshold and top-K in
train.pyandtest.py. - Can calculate the evaluation metrics --- AUC & AUPRC.
- Can create the prediction file which including the predicted values and predicted labels of the Testset data in
test.py. - Add other useful data preprocess functions in
data_helpers.py. - Use
loggingfor helping to record the whole info (including parameters display, model training info, etc.). - Provide the ability to save the best n checkpoints in
checkmate.py, whereas thetf.train.Savercan only save the last n checkpoints.
Data
See data format in /data folder which including the data sample files. For example:
{"testid": "3935745", "features_content": ["pore", "water", "pressure", "metering", "device", "incorporating", "pressure", "meter", "force", "meter", "influenced", "pressure", "meter", "device", "includes", "power", "member", "arranged", "control", "pressure", "exerted", "pressure", "meter", "force", "meter", "applying", "overriding", "force", "pressure", "meter", "stop", "influence", "force", "meter", "removing", "overriding", "force", "pressure", "meter", "influence", "force", "meter", "resumed"], "labels_index": [526, 534, 411], "labels_num": 3}
- "testid": just the id.
- "features_content": the word segment (after removing the stopwords)
- "labels_index": The label index of the data records.
- "labels_num": The number of labels.
Text Segment
-
You can use
nltkpackage if you are going to deal with the English text data. -
You can use
jiebapackage if you are going to deal with the Chinese text data.
Data Format
This repository can be used in other datasets (text classification) in two ways:
- Modify your datasets into the same format of the sample.
- Modify the data preprocessing code in
data_helpers.py.
Anyway, it should depend on what your data and task are.
🤔Before you open the new issue about the data format, please check the data_sample.json and read the other open issues first, because someone maybe ask me the same question already. For example:
- 输入文件的格式是什么样子的?
- Where is the dataset for training?
- 在 data_helpers.py 中的 content.txt 与 metadata.tsv 是什么,具体格式是什么,能否提供一个样例?
Pre-trained Word Vectors
You can download the Word2vec model file (dim=100). Make sure they are unzipped and under the /data folder.
You can pre-training your word vectors (based on your corpus) in many ways:
- Use
gensimpackage to pre-train data. - Use
glovetools to pre-train data. - Even can use a fasttext network to pre-train data.
Usage
See Usage.
Network Structure
FastText
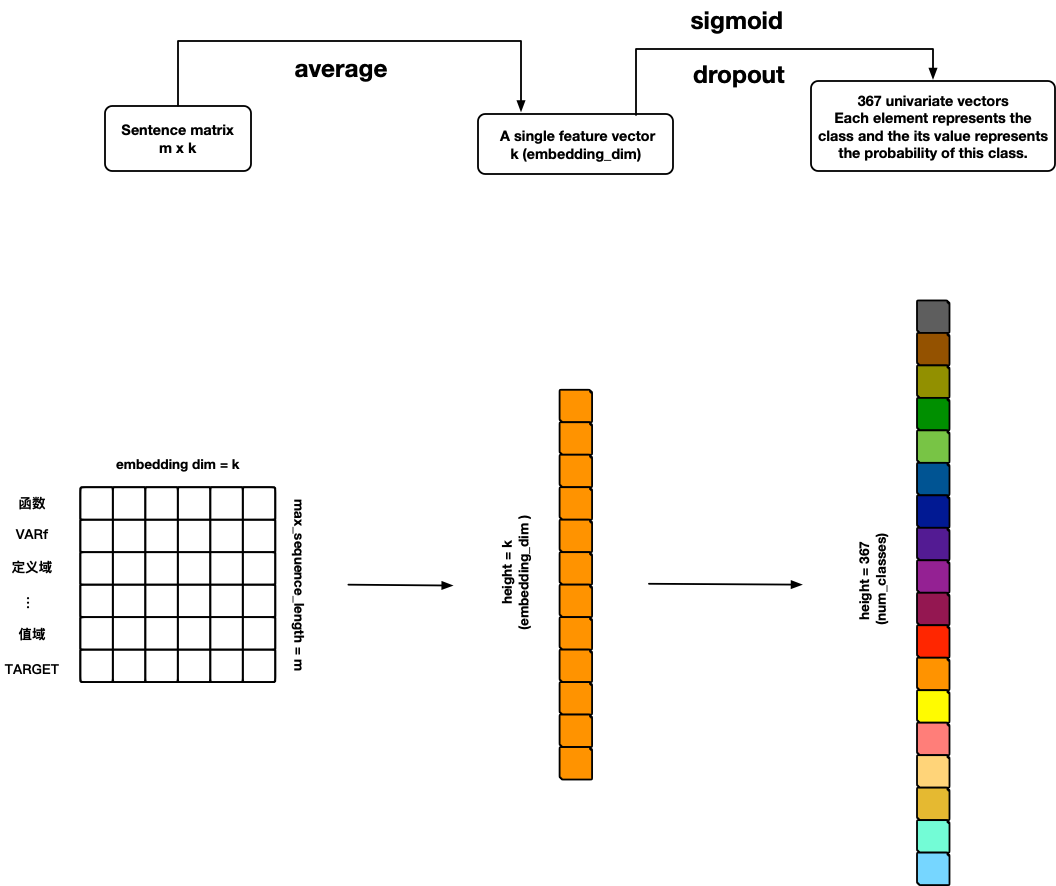
References:
TextANN
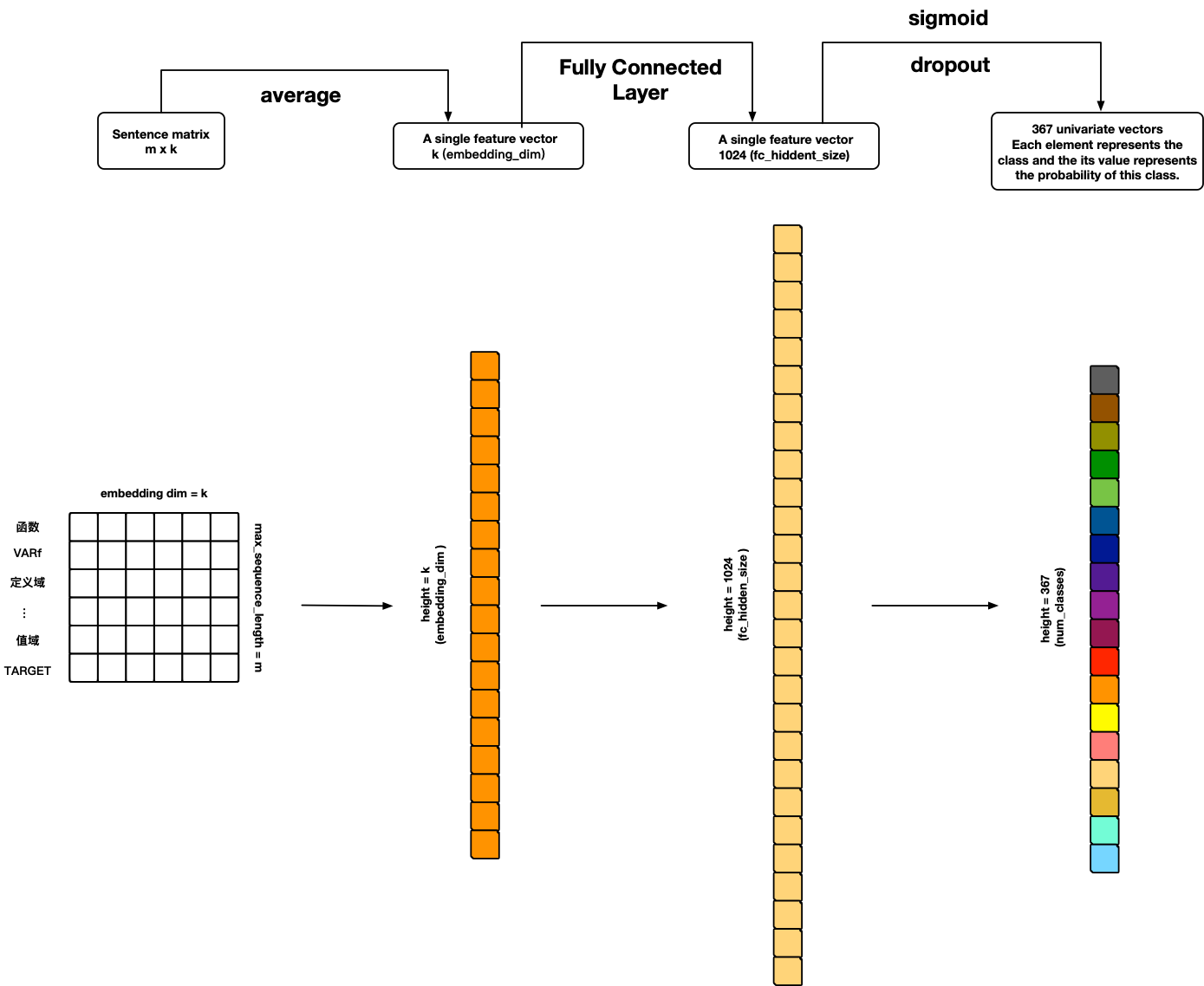
References:
- Personal ideas 🙃
TextCNN
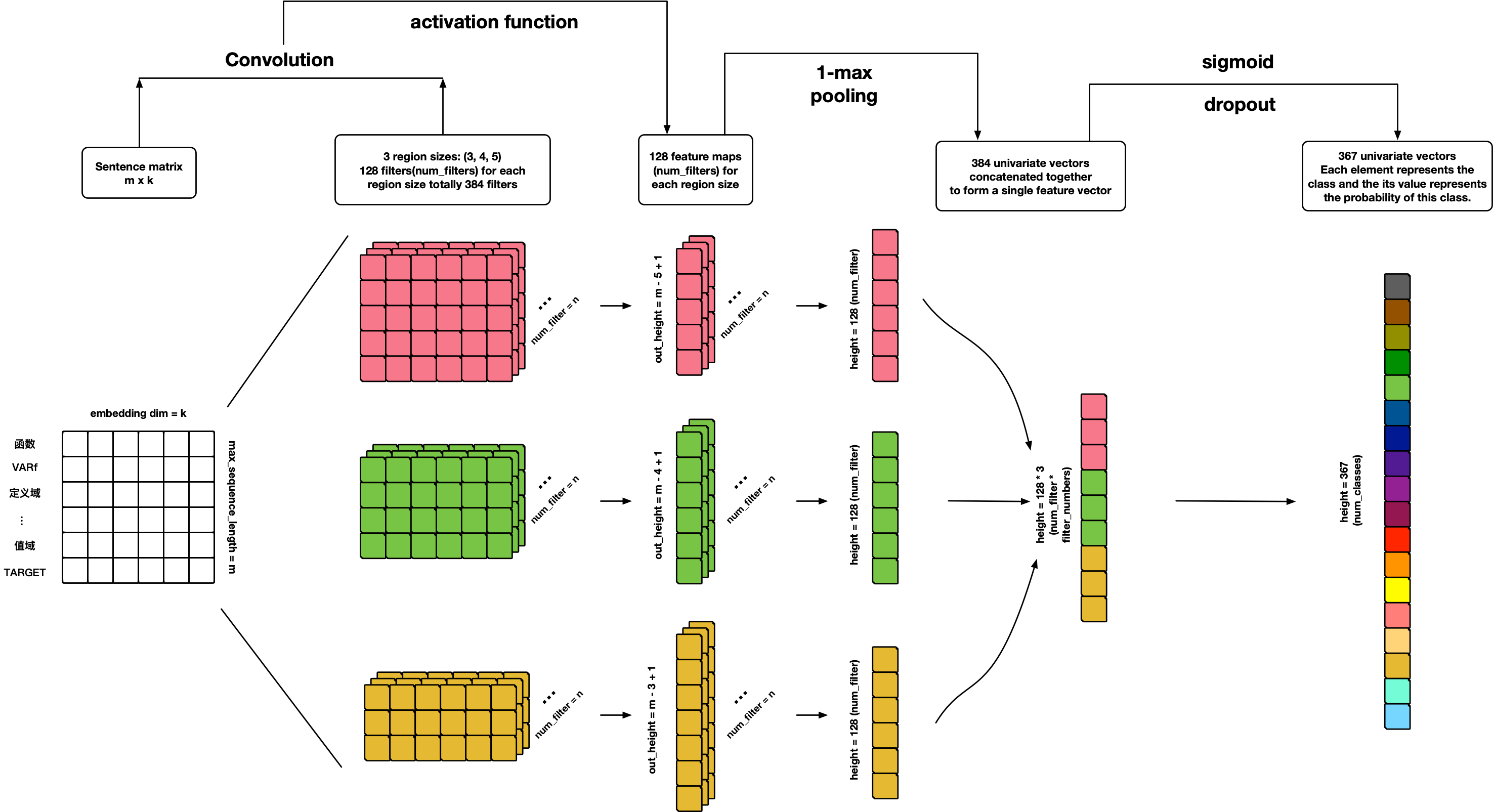
References:
- Convolutional Neural Networks for Sentence Classification
- A Sensitivity Analysis of (and Practitioners' Guide to) Convolutional Neural Networks for Sentence Classification
TextRNN
Warning: Model can use but not finished yet 🤪!
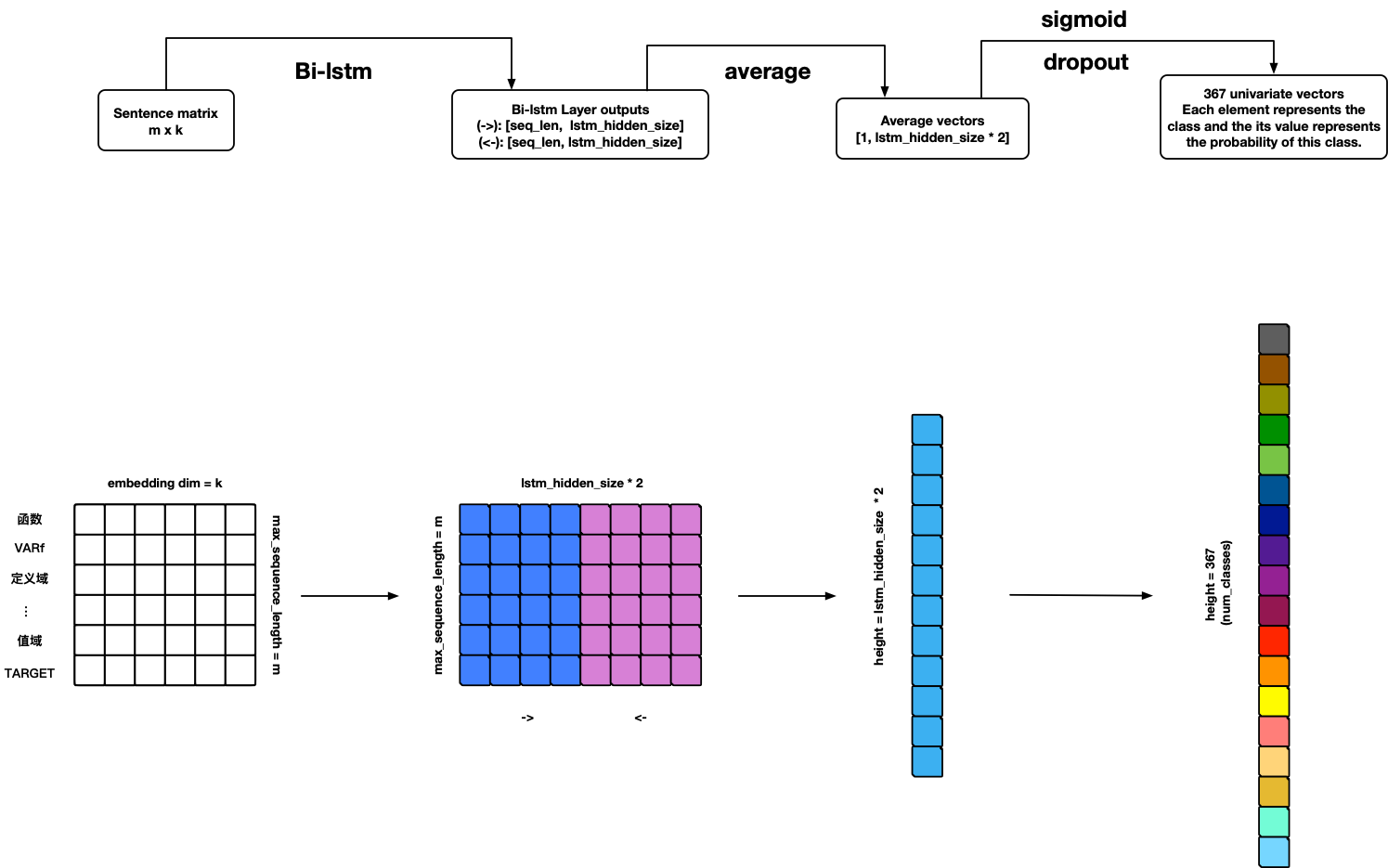
TODO
- Add BN-LSTM cell unit.
- Add attention.
References:
TextCRNN
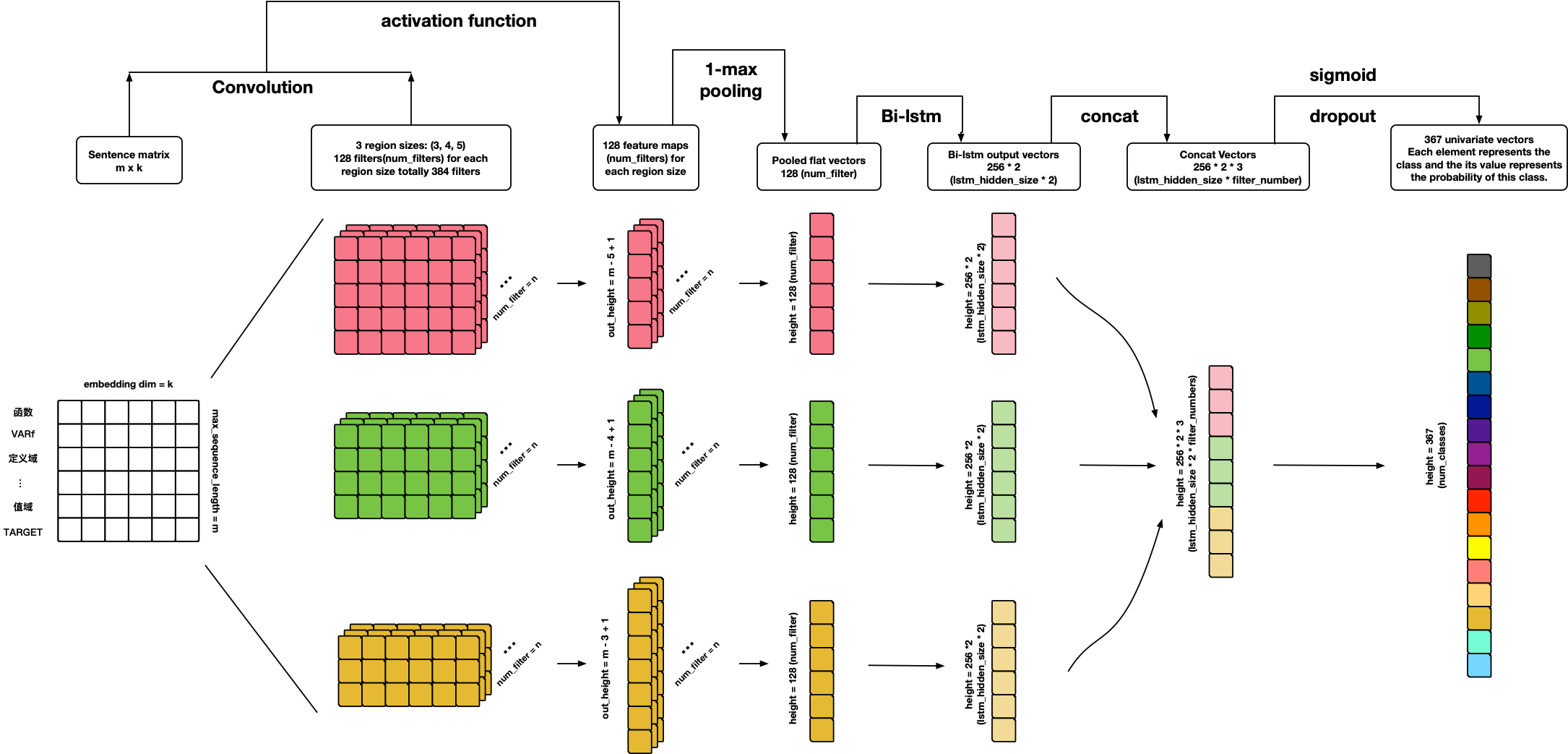
References:
- Personal ideas 🙃
TextRCNN
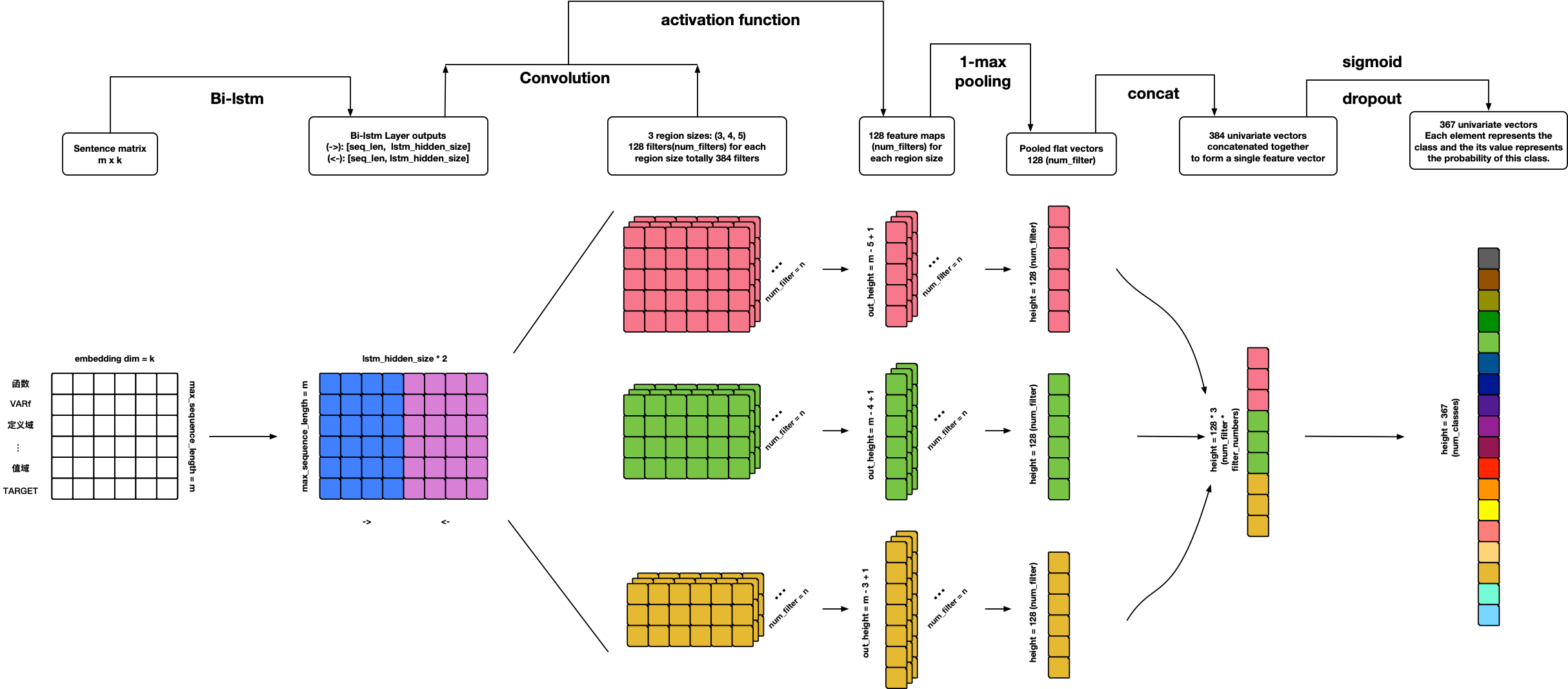
References:
- Personal ideas 🙃
TextHAN
References:
TextSANN
Warning: Model can use but not finished yet 🤪!
TODO
- Add attention penalization loss.
- Add visualization.
References:
About Me
黄威,Randolph
SCU SE Bachelor; USTC CS Ph.D.
Email: [email protected]
My Blog: randolph.pro
LinkedIn: randolph's linkedin