dionhaefner / Pyhpc Benchmarks
Programming Languages
Projects that are alternatives of or similar to Pyhpc Benchmarks
HPC benchmarks for Python
This is a suite of benchmarks to test the sequential CPU and GPU performance of various computational backends with Python frontends.
Specifically, we want to test which high-performance backend is best for geophysical (finite-difference based) simulations.
Contents
FAQ
Why?
The scientific Python ecosystem is thriving, but high-performance computing in Python isn't really a thing yet. We try to change this with our pure Python ocean simulator Veros, but which backend should we use for computations?
Tremendous amounts of time and resources go into the development of Python frontends to high-performance backends, but those are usually tailored towards deep learning. We wanted to see whether we can profit from those advances, by (ab-)using these libraries for geophysical modelling.
Why do the benchmarks look so weird?
These are more or less verbatim copies from Veros (i.e., actual parts of a physical model).
Most earth system and climate model components are based on finite-difference schemes to compute derivatives. This can be represented
in vectorized form by index shifts of arrays (such as 0.5 * (arr[1:] + arr[:-1]), the first-order derivative of arr at every point). The most common index range is [2:-2], which represents the full domain (the two outermost grid cells are overlap / "ghost cells" that allow us to shift the array across the boundary).
Now, maths is difficult, and numerics are weird. When many different physical quantities (defined on different grids) interact, things get messy very fast.
Why only test sequential CPU performance?
Two reasons:
- I was curious to see how good the compilers are without being able to fall back to thread parallelism.
- In many physical models, it is pretty straightforward to parallelize the model "by hand" via MPI. Therefore, we are not really dependent on good parallel performance out of the box.
Which backends are currently supported?
(not every backend is available for every benchmark)
What is included in the measurements?
Pure time spent number crunching. Preparing the inputs, copying stuff from and to GPU, compilation time, time it takes to check results etc. are excluded. This is based on the assumption that these things are only done a few times per simulation (i.e., that their cost is amortized during long-running simulations).
How does this compare to a low-level implementation?
As a rule of thumb (from our experience with Veros), the performance of a Fortran implementation is very close to that of the Numba backend, or ~3 times faster than NumPy.
Environment setup
For CPU:
$ conda create -f environment_cpu.yml
$ conda activate pyhpc-bench-cpu
GPU:
$ conda create -f environment_gpu.yml
$ conda activate pyhpc-bench-gpu
If you prefer to install things by hand, just have a look at the environment files to see what you need. You don't need to install all backends; if a module is unavailable, it is skipped automatically.
Usage
Your entrypoint is the script run.py:
$ python run.py --help
Usage: run.py [OPTIONS] BENCHMARK
HPC benchmarks for Python
Usage:
$ python run.py benchmarks/<BENCHMARK_FOLDER>
Examples:
$ taskset -c 0 python run.py benchmarks/equation_of_state
$ python run.py benchmarks/equation_of_state -b numpy -b jax --device
gpu
More information:
https://github.com/dionhaefner/pyhpc-benchmarks
Options:
-s, --size INTEGER Run benchmark for this array size
(repeatable) [default: 4096, 16384, 65536,
262144, 1048576, 4194304]
-b, --backend [numpy|bohrium|cupy|jax|theano|numba|pytorch|tensorflow]
Run benchmark with this backend (repeatable)
[default: run all backends]
-r, --repetitions INTEGER Fixed number of iterations to run for each
size and backend [default: auto-detect]
--burnin INTEGER Number of initial iterations that are
disregarded for final statistics [default:
1]
--device [cpu|gpu|tpu] Run benchmarks on given device where
supported by the backend [default: cpu]
--help Show this message and exit.
Benchmarks are run for all combinations of the chosen sizes (-s) and backends (-b), in random order.
CPU
Some backends refuse to be confined to a single thread, so I recommend you wrap your benchmarks
in taskset to set processor affinity to a single core (only works on Linux):
$ conda activate pyhpc-bench-cpu
$ taskset -c 0 python run.py benchmarks/<benchmark_name>
GPU
Some backends use all available GPUs by default, some don't. If you have multiple GPUs, you can set the
one to be used through CUDA_VISIBLE_DEVICES, so keep things fair.
$ conda activate pyhpc-bench-gpu
$ export CUDA_VISIBLE_DEVICES="0"
$ python run.py benchmarks/<benchmark_name> --gpu
Some backends are pretty greedy with allocating memory. For large problem sizes, it can be a good idea to only run one backend at a time (and NumPy for reference):
$ conda activate pyhpc-bench-gpu
$ export CUDA_VISIBLE_DEVICES="0"
$ for backend in bohrium jax cupy pytorch tensorflow; do
... python run benchmarks/<benchmark_name> --device gpu -b $backend -b numpy -s 10_000_000
... done
Example results
Summary
Equation of state


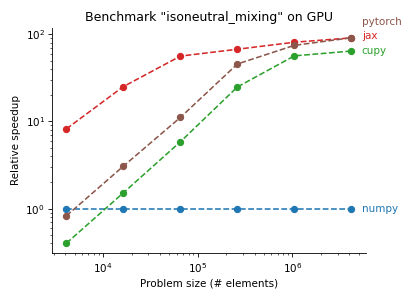
Isoneutral mixing

Turbulent kinetic energy


Full reports
- Example results on bare metal with Tesla P100 GPU (more reliable)
- Example results on Google Colab (easier to reproduce)
Conclusion
Lessons I learned by assembling these benchmarks: (your mileage may vary)
- The performance of Jax seems very competitive, both on GPU and CPU. It is consistently among the top implementations on CPU, and shows the best performance on GPU.
- Jax' performance on GPU seems to be quite hardware dependent. Jax performance significantly better (relatively speaking) on a Tesla P100 than a Tesla K80.
- Numba is a great choice on CPU if you don't mind writing explicit for loops (which can be more readable than a vectorized implementation), being slightly faster than Jax with little effort.
- If you have embarrasingly parallel workloads, speedups of > 1000x are easy to achieve on high-end GPUs.
- Tensorflow is not great for applications like ours, since it lacks tools to apply partial updates to tensors (in the sense of
tensor[2:-2] = 0.). - Don't bother using Pytorch or vanilla Tensorflow on CPU (you won't get much faster than NumPy). Tensorflow with XLA (
experimental_compile) is great though! - CuPy is nice! Often you don't need to change anything in your NumPy code to have it run on GPU (with decent, but not outstanding performance).
- Reaching Fortran performance on CPU with vectorized implementations is hard :)
Contributing
Community contributions are encouraged! Whether you want to donate another benchmark, share your experience, optimize an implementation, or suggest another backend - feel free to ask or open a PR.