Recurrent-Deep-Q-Learning
Introduction
Partially Observable Markov Decision Process (POMDP) is a generalization of Markov Decision Process where agent cannot directly observe the underlying state and only an observation is available. Earlier methods suggests to maintain a belief (a pmf) over all the possible states which encodes the probability of being in each state. This quickly limits the size of the problem to which we can use this method. However, the paper Playing Atari with Deep Reinforcement Learning presented an approach which uses last 4 observations as input to the learning algorithm, which can be seen as 4th order markov decision process. Many papers suggest that much performance can be obtained if we use more than last 4 frames but this is expensive from computational and storage point of view (experience replay). Recurrent networks can be used to summarize what agent has seen in past observations. In this project, I investgated this using a simple Partially Observable Environment and found that using a single recurrent layer able to achieve much better performance than using some last k-frames.
Environment
Environment used was a 9x9 grid where Red colored blocks represents agent location in the grid. Green colored blocks are the goal points for agent. Blue colored blocks are the blocks which agent needs to avoid. A reward of +1 is given to agent when it eats green block. A reward of -1 is given to the agent when it eats blue block. Other movements results in zero. Observation is the RGB image of neigbouring cells of agent. Below figure describes the observation.
| Underlying MDP | Observation to Agent |
|---|---|
.png) |
 |
Algorithm

How to Run ?
I ran the experiment for the following cases. The corresponding code/jupyter files are linked to each experiment.
- MDP Case - The underlying state was fully visible. The whole grid was given as the input to the agent.
- Single Observation - In this case, the most recent observation was used as the input to agent.
- Last Two Observations - In this case, the last two most recent observation was used as the input to agent to encode the temporal information among observations.
- LSTM Case - In this case, an LSTM layer is used to pass the temporal information among observations.
Learned Policies
| Fully Observable | Single Observation | LSTM |
|---|---|---|
 |
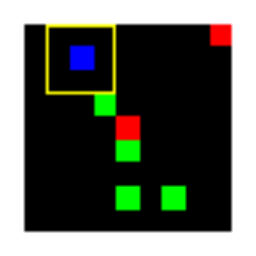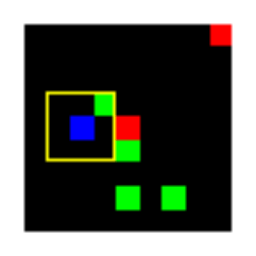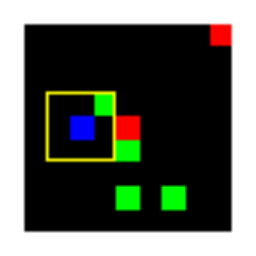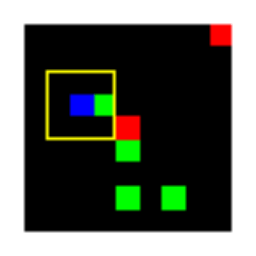 |
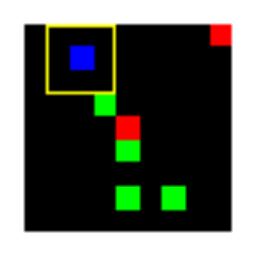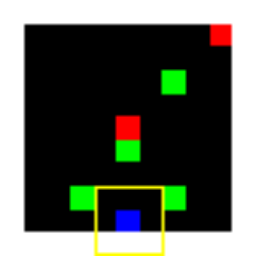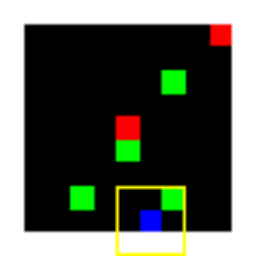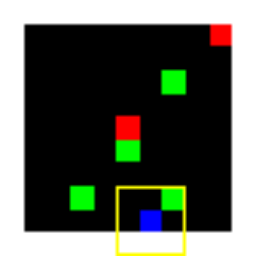 |
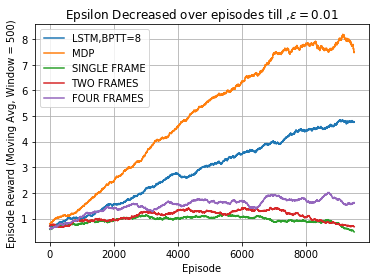
Results
The figure given below compares the performance of different cases. MDP case is the best we can do as the underlying state is fully visible to the agent. However, the challenge is to perform better given an observation. The graph clearly shows the LSTM consistently performed better as the total reward per episode was much higher than using some last k-frames.
References
- Deep Recurrent Q Learning for POMDPs
- Recurrent Neural Networks for Reinforcement Learning: an Investigation of Relevant Design Choices
- Grid World POMDP Environment
Requirements
- Python >= 3.5
- PyTorch >= 0.4.1