![]()
![]()
![]()
Reccurent neural network
In the process of designing systems that can adapt and learn patterns we explore on a basic, fundamental, level theories about how complex biological systems, such as human brains, work. I find this very fascinating. A recurrent neural network is a system that contains feedback loops and can store information from the past. This is necessary in order to model long-term dependencies such as can be found in natural language processing.
This program will learn to produce text similar to the one that it has been training on using a LSTM network implemented in C. The repo is inspired by Andrej Karpathys char-rnn: https://github.com/karpathy/char-rnn but instead implemented in C to be used in more constrained environments.
Build
CMake
This is the preferred way to build it on Windows.
# Build using cmake
mkdir build
cd build
cmake ..
cmake --build .Meson
This works on multiple platform, the only requirement is Python3.
# Create virtual environment
python3 -m venv venv
# Activate virtual environment
# On Linux:
source venv/bin/activate
# On Windows:
venv\Script\activate
# Install requirements
pip install -r requirements.txt
meson builddir
cd builddir
ninjaUnix Makefile
# Build using make and GCC
makeRunning
Do you have a mac or a Linux machine? In that case it is super easy to download and run.
Mac or Linux (UNIX types)
Open a terminal window and type:
# (You may have to install 'git', if you don't already have it!)
git clone https://github.com/Ricardicus/recurrent-neural-net/
cd recurrent-neural-net
# This will compile the program. You need the compiler 'gcc' which is also available for download just like 'git'.
makeIf there is any complaints, then remove some flags in the 'makefile', I use 'msse3' on my mac but it does not work for my raspberry Pi for example.
Then run the program:
./net datafile where datafile is a file with the traning data and it will start training on it. You can see the progress over time.
Windows
Build using CMake or meson. Run with the same arguments as in UNIX.
Configure default behaviour before build
Check out the file "std_conf.h".
In std_conf.h you can edit the program. You can edit the hyperparameters such as learning rate etc, set the number of layers (2/3 is best I think), set how often it should output data etc. If you edit this file, you edit the source code and you will need to rebuild the program with the command "make". You can also use input arguments to set some of the behaviour.
Running the program with no arguments triggers the help output to be displayed. This help shows what flags can be passed as arguments to the program to modify its behaviour. The output looks like this:
Usage: ./net datafile [flag value]*
Flags can be used to change the training procedure.
The flags require a value to be passed as the following argument.
E.g., this is how you train with a learning rate set to 0.03:
./net datafile -lr 0.03
The following flags are available:
-r : read a previously trained network, the name of which is currently configured to be 'lstm_net.net'.
-lr : learning rate that is to be used during training, see the example above.
-it : the number of iterations used for training (not to be confused with epochs).
-ep : the number of epochs used for training (not to be confused with iterations).
-mb : mini batch size.
-dl : decrease the learning rate over time, according to lr(n+1) <- lr(n) / (1 + n/value).
-st : number of iterations between how the network is stored during training. If 0 only stored once after training.
-out: number of characters to output directly, note: a network and a datafile must be provided.
-L : Number of layers, may not exceed 10
-N : Number of neurons in every layer
-vr : Verbosity level. Set to zero and only the loss function after and not during training will be printed.
-c : Don't train, only generate output. Seed given by the value. If -r is used, datafile is not considered.
-s : Save folder, where models are stored (binary and JSON).
Check std_conf.h to see what default values are used, these are set during compilation.
./net compiled Jan 18 2021 13:08:35
The -st flags is great. Per default the network is stored upon interrupting the program with Ctrl-C. But using this argument, you can let the program train and have it store the network continously during the training process. In that case the network is avaiable for you even if the program is unexpectedly terminated.
Enjoy! :)
Examples
I trained this program to read the first Harry Potter book, It produced quotes such as this:
Iteration: 303400, Loss: 0.07877, output: ed Aunt Petunia suggested
timidly, hours later, but Uncle Vernon was pointing at what had a thing while the next day. The Dursleys swut them on, the boy.
It has definately learned something as it is writing in english, and I only model on the most general basis, the character codes.
For more activity based on this neural network, check out my twitter bot: https://twitter.com/RicardicusPi
Comments
I figured if it was to be implemented in C instead of Python then there would be a huge speedup which the results show!
I will give this some time and hopefully I figure out a way that optimizes the program even more for speed.. Until then, have a go at this little program and edit it as you please!
Mathematical expressions
This is the model I use for a single LSTM cell:
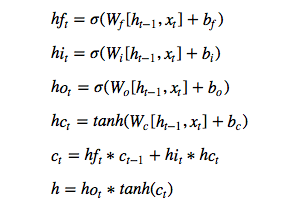
That image describes a single layer forward pass. The terminology in the codebase are derived from that notation. So for example, if you wonder what model->Wf means, then Wf is represented in that set of expressions. Also, model->dldWf means the backpropagated gradients for Wf. I connect the layers with a fully connected layer, introducing Wy and by also. Inputs to the fully connected is the array h in the set of expressions above. I apply a softmax to output layer of the model also in the end, to get the probabilities.
Docker
I have built a container for this, it just trains a network at the moment. Take a look at Dockerfile. Modify at will. Here is a container for training on the poetic edda:
# Pulls an image that trains the network on the poetic Edda by default,
# but can also train on your own, other data.
docker pull rickardhallerback/recurrent-neural-net:1.1
# Run the image, training on the poetic Edda (default)
docker run rickardhallerback/recurrent-neural-net:1.1
# Run the image, training on your own file, in the current working
# directory, say 'myfile.txt'. Storing model anew every 1000th iteration.
docker run -v $(pwd):/data rickardhallerback/recurrent-neural-net:1.1 /data/myfile.txt -s /data -st 1000Additional interesting stuff
Under the folder 'html' you will find a document that can be used to play around with pre-trained models.
Below is an image of this GUI and how one can interact with it.
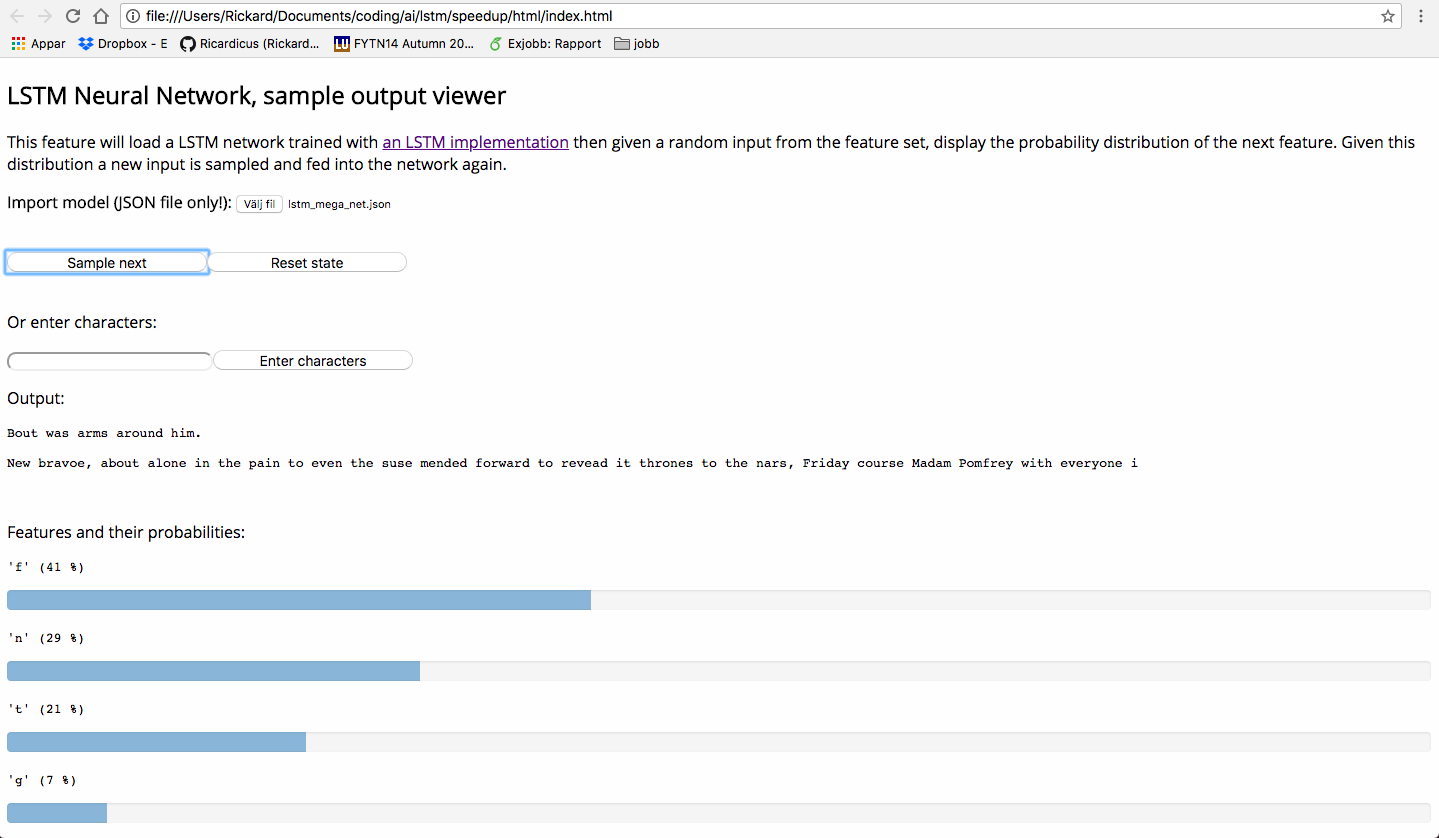
In the image of the GUI above, we see that a word is about to be formed starting with the letter i. The most likely words to be formed are: if, in and it.