liyibo / Text Classification Demos
Programming Languages
Projects that are alternatives of or similar to Text Classification Demos
Text classification demos
Tensorflow 环境下,不同的神经网络模型对中文文本进行分类,本文中的 demo 都是字符级别的文本分类(增加了word-based 的统计结果),简化了文本分类的流程,字符级别的分类在有些任务上的效果可能不好,需要结合实际情况添加自定义的分词模块。
数据集
下载地址: https://pan.baidu.com/s/1hugrfRu 密码: qfud
使用 THUCNews 的一个子集进行训练与测试,使用了其中的 10 个分类,每个分类 6500 条数据。
类别如下:
体育, 财经, 房产, 家居, 教育, 科技, 时尚, 时政, 游戏, 娱乐
数据集划分如下:
训练集: 5000 * 10
验证集: 500 * 10
测试集: 1000 * 10
具体介绍请参考:text-classification-cnn-rnn
分类效果
- char-based
| model | fasttext | cnn | rnn | rcnn | han | dpcnn | bert |
|---|---|---|---|---|---|---|---|
| val_acc | 92.92 | 93.56 | 93.56 | 94.36 | 93.94 | 93.70 | 97.84 |
| test_acc | 93.15 | 94.57 | 94.37 | 95.53 | 93.65 | 94.87 | 96.93 |
- word-based
| model | fasttext | cnn | rnn | rcnn | han | dpcnn | bert |
|---|---|---|---|---|---|---|---|
| val_acc | 95.52 | 95.28 | 93.10 | 95.60 | 95.10 | 95.68 | - |
| test_acc | 95.34 | 95.77 | 94.05 | 96.36 | 95.66 | 95.97 | - |
模型介绍
1、FastText
fasttext_model.py 文件为训练和测试 fasttext 模型的代码
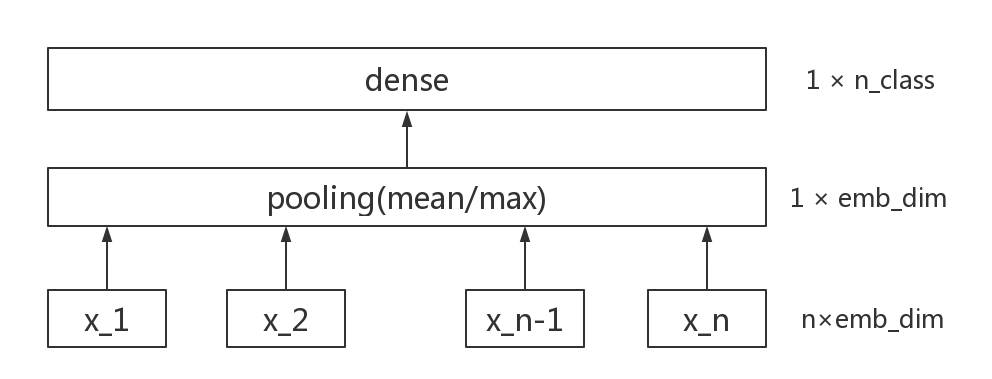
本代码简化了 fasttext 模型的结构,模型结构非常简单,运行速度简直飞快,模型准确率也不错,可根据实际需要优化模型结构
2、TextCNN
cnn_model.py 文件为训练和测试 TextCNN 模型的代码
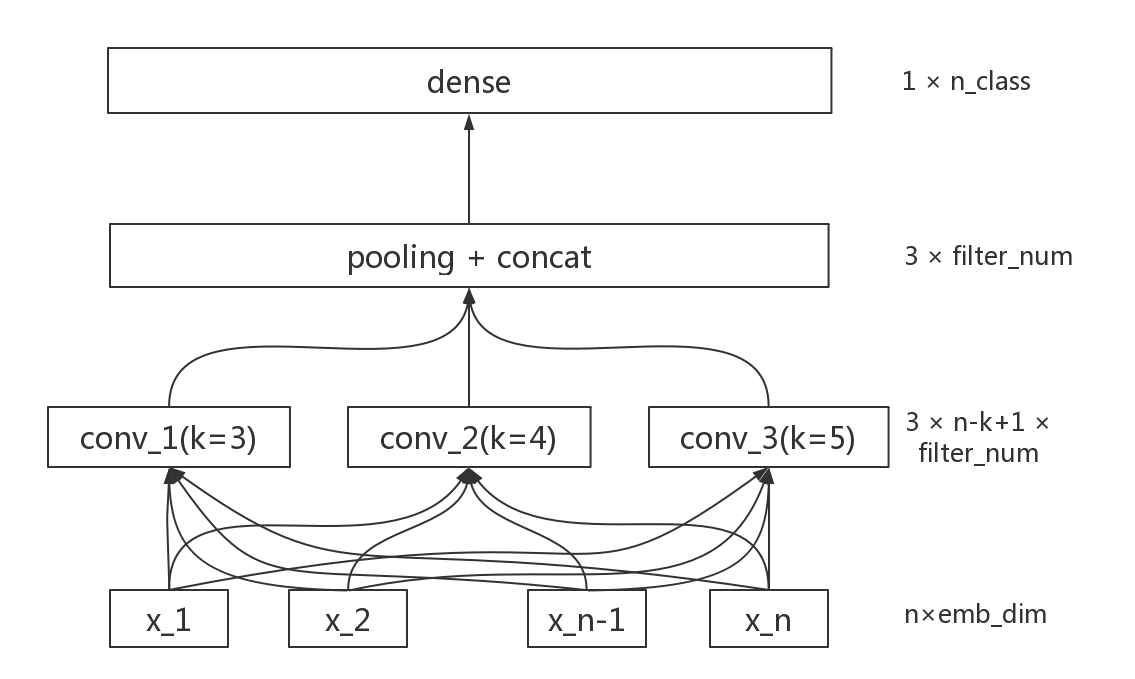
本代码实现了 TextCNN 模型的结构,通过 3 个不同大小的卷积核,对输入文本进一维卷积,分别 pooling 三个卷积之后的 feature, 拼接到一起,然后进行 dense 操作,最终输出模型结果。可实现速度和精度之间较好的折中。
3、RNN
rnn_model.py 文件为训练和测试 TextCNN 模型的代码
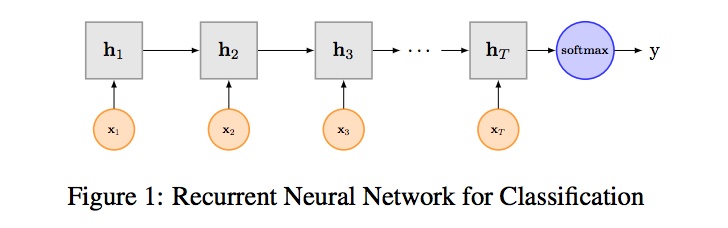
本代码实现了 TextRNN 模型的结构,对输入序列进行embedding,然后输入两层的 rnn_cell中学习序列特征,取最后一个 word 的 state 作为进行后续的 fc 操作,最终输出模型结果。
4、RCNN
rcnn_model.py 文件为训练和测试 RCNN 模型的代码

Recurrent Convolutional Neural Network for Text Classification, 在学习 word representations 时候,同时采用了 rnn 结构来学习 word 的上下文,虽然模型名称为 RCNN,但并没有显式的存在卷积操作。
1、采用双向lstm学习 word 的上下文
c_left = tf.concat([tf.zeros(shape), output_fw[:, :-1]], axis=1, name="context_left")
c_right = tf.concat([output_bw[:, 1:], tf.zeros(shape)], axis=1, name="context_right")
word_representation = tf.concat([c_left, embedding_inputs, c_right], axis=2, name="last")
2、pooling + softmax
word_representation 的维度是 batch_size * seq_length * 2 * context_dim + embedding_dim
在 seq_length 维度进行 max pooling,然后进行 fc 操作就可以进行分类了,可以将该网络看成是 fasttext 的改进版本
5、HAN
han_model.py 文件为训练和测试 HAN 模型的代码
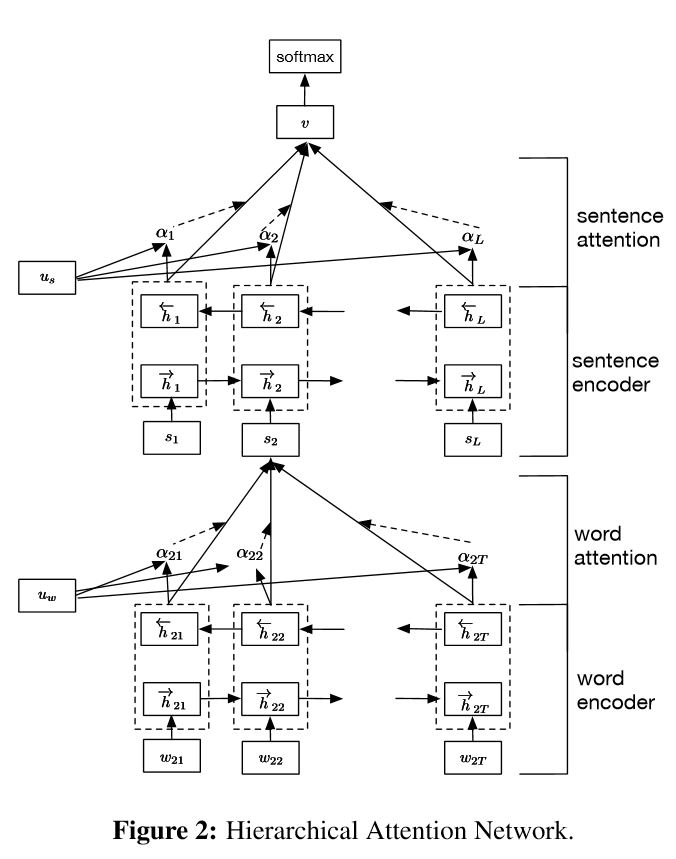
HAN 为 Hierarchical Attention Networks,将待分类文本,分为一定数量的句子,分别在 word level 和 sentence level 进行 encoder 和 attention 操作,从而实现对较长文本的分类。
本文是按照句子长度将文本分句的,实际操作中可按照标点符号等进行分句,理论上效果能好一点。
-
1、对文本进行分句
对每个句子进行双向lstm编码
batch_size = 64, seq_length = 600, sent_num = 10, emb_size = 128, lstm_hid_dim = 256
数据维度变化:64 * 600 * 128 --- (64*10) * 60 * 128 --- (64*10) * 60 * 512
-
2、word level attention
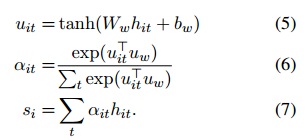
(1) 将输入的lstm编码结果做一次非线性变换,可以看做是输入编码的hidden representation, shape = (64*10) * 60 * 256
(2) 将 hidden representation 与一个学习得到的 word level context vector 的相似性进行 softmax,得到每个单词在句子中的权重
(3) 对输入的lstm 编码进行加权求和,得到句子的向量表示
数据维度变化:(64*10) * 60 * 512 --- (64*10) * 512
-
3、得到每个句子的向量表示
-
4、sentence level attention
与 word level attention 过程一样,只是该层是句子级别的attention
数据维度变化:64 * 10 * 512 --- 64 * 512
-
5、得到 document 的向量表示
-
6、dence + softmax
6、DPCNN
dpcnn_model.py 文件为训练和测试 DPCNN 模型的代码
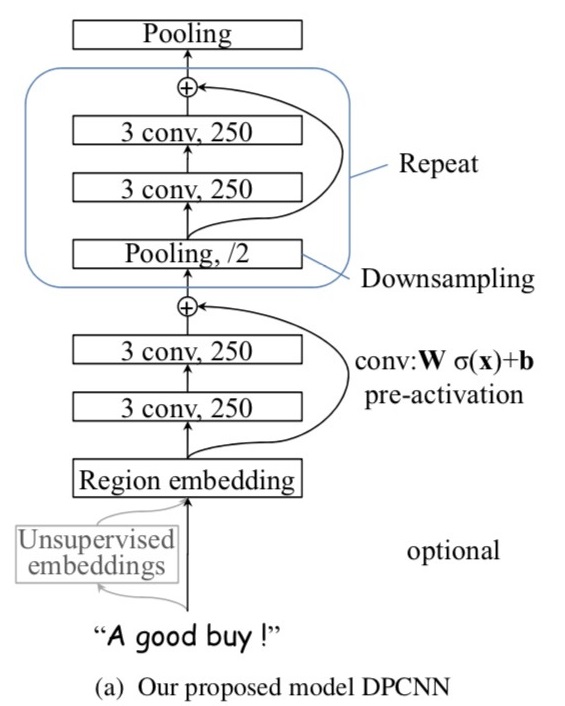
DPCNN 通过卷积和残差连接增加了以往用于文本分类 CNN 网络的深度,可以有效提取文本中的远程关系特征,并且复杂度不高,实验表名,效果比以往的 CNN 结构要好一点。
- region_embedding: word_embedding 之后进行的 ngram 卷积结果
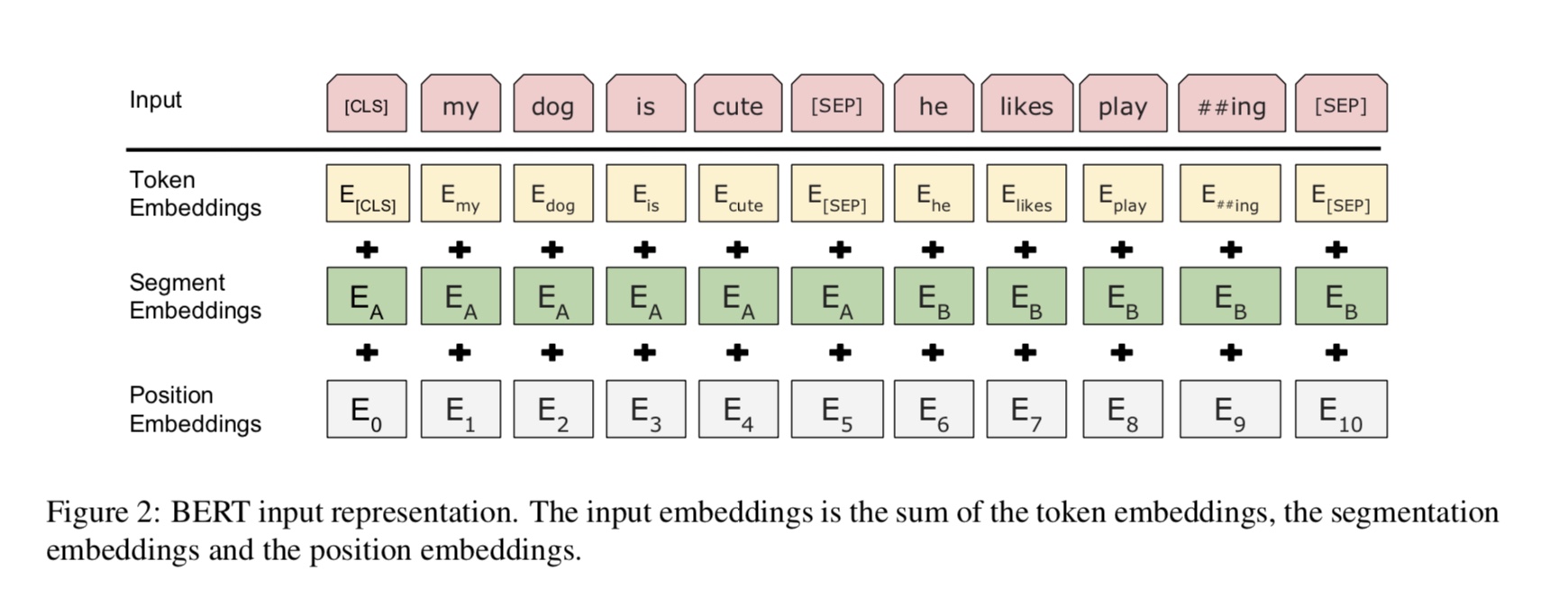
7、BERT
bert_model.py 文件为训练和测试 BERT 模型的代码
google官方提供用于文本分类的demo写的比较抽象,所以本文基于 google 提供的代码和初始化模型,重写了文本分类模型的训练和测试代码,bert 分类模型在小数据集下效果很好,通过较少的迭代次数就能得到很好的效果,但是训练和测试速度较慢,这点不如基于 CNN 的网络结构。
bert_model.py 将训练数据和验证数据存储为 tfrecord 文件,然后进行训练
由于 bert 提供的预训练模型较大,需要自己去 google-research/bert 中下载预训练好的模型,本实验采用的是 "BERT-Base, Chinese" 模型。