tim5go / Cnn Question Classification Keras
Chinese Question Classifier (Keras Implementation) on BQuLD
Stars: ✭ 28
Programming Languages
python
139335 projects - #7 most used programming language
Projects that are alternatives of or similar to Cnn Question Classification Keras
Text Classification Cnn Rnn
CNN-RNN中文文本分类,基于TensorFlow
Stars: ✭ 3,613 (+12803.57%)
Mutual labels: chinese, classification, cnn, text-classification
Nlp chinese corpus
大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP
Stars: ✭ 6,656 (+23671.43%)
Mutual labels: chinese, question-answering, text-classification, chinese-nlp
Chinese Text Classification
Chinese-Text-Classification,Tensorflow CNN(卷积神经网络)实现的中文文本分类。QQ群:522785813,微信群二维码:http://www.tensorflownews.com/
Stars: ✭ 284 (+914.29%)
Mutual labels: chinese, cnn, text-classification
Rmdl
RMDL: Random Multimodel Deep Learning for Classification
Stars: ✭ 375 (+1239.29%)
Mutual labels: classification, cnn, text-classification
Cnn Text Classification Tf Chinese
CNN for Chinese Text Classification in Tensorflow
Stars: ✭ 237 (+746.43%)
Mutual labels: chinese, cnn, text-classification
Eda nlp
Data augmentation for NLP, presented at EMNLP 2019
Stars: ✭ 902 (+3121.43%)
Mutual labels: classification, cnn, text-classification
Food Recipe Cnn
food image to recipe with deep convolutional neural networks.
Stars: ✭ 448 (+1500%)
Mutual labels: classification, cnn
Cluepretrainedmodels
高质量中文预训练模型集合:最先进大模型、最快小模型、相似度专门模型
Stars: ✭ 493 (+1660.71%)
Mutual labels: chinese, text-classification
Servenet
Service Classification based on Service Description
Stars: ✭ 21 (-25%)
Mutual labels: classification, cnn
Eda nlp for chinese
An implement of the paper of EDA for Chinese corpus.中文语料的EDA数据增强工具。NLP数据增强。论文阅读笔记。
Stars: ✭ 660 (+2257.14%)
Mutual labels: chinese, text-classification
Textclassificationbenchmark
A Benchmark of Text Classification in PyTorch
Stars: ✭ 534 (+1807.14%)
Mutual labels: cnn, text-classification
Text Classification
Implementation of papers for text classification task on DBpedia
Stars: ✭ 682 (+2335.71%)
Mutual labels: cnn, text-classification
Zhparser
zhparser is a PostgreSQL extension for full-text search of Chinese language
Stars: ✭ 418 (+1392.86%)
Mutual labels: chinese, chinese-nlp
Tensorflow Tutorial
Tensorflow tutorial from basic to hard, 莫烦Python 中文AI教学
Stars: ✭ 4,122 (+14621.43%)
Mutual labels: classification, cnn
Text classification
all kinds of text classification models and more with deep learning
Stars: ✭ 7,179 (+25539.29%)
Mutual labels: classification, text-classification
Multi Class Text Classification Cnn
Classify Kaggle Consumer Finance Complaints into 11 classes. Build the model with CNN (Convolutional Neural Network) and Word Embeddings on Tensorflow.
Stars: ✭ 410 (+1364.29%)
Mutual labels: cnn, text-classification
Multi Class Text Classification Cnn Rnn
Classify Kaggle San Francisco Crime Description into 39 classes. Build the model with CNN, RNN (GRU and LSTM) and Word Embeddings on Tensorflow.
Stars: ✭ 570 (+1935.71%)
Mutual labels: cnn, text-classification
Tensorflow cookbook
Code for Tensorflow Machine Learning Cookbook
Stars: ✭ 5,984 (+21271.43%)
Mutual labels: classification, cnn
Lightnlp
基于Pytorch和torchtext的自然语言处理深度学习框架。
Stars: ✭ 739 (+2539.29%)
Mutual labels: chinese, text-classification
Artificial Adversary
🗣️ Tool to generate adversarial text examples and test machine learning models against them
Stars: ✭ 348 (+1142.86%)
Mutual labels: classification, text-classification
Recurrent Convolutional Neural Networks for Chinese Question Classification on BQuLD
A deep learning-based Chinese question classifier (Keras implementation) on BQuLD
Contents
- Model Architecture Overview
- Bilingual Question Labelling Dataset (BQuLD)
- Embedding Preparation
- Result
Model Architecture Overview
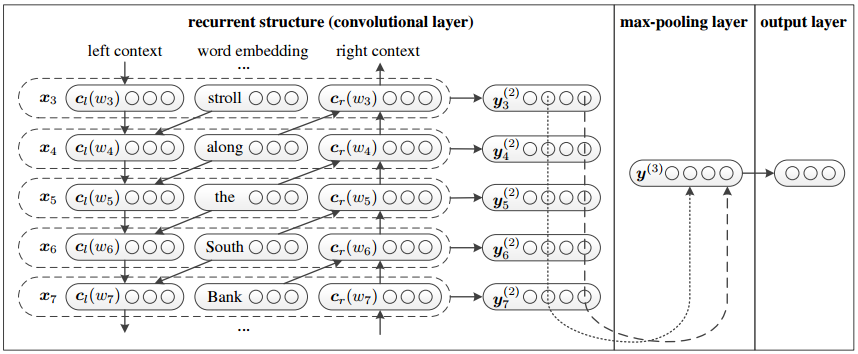
For more details Click Here.
Bilingual Question Labelling Dataset (BQuLD)
This dataset is a bilingual (traditional Chinese & English) question labelling dataset designed for NLP researchers.
The questinon type definition is borrowed from Intelligent Agent Systems Lab:
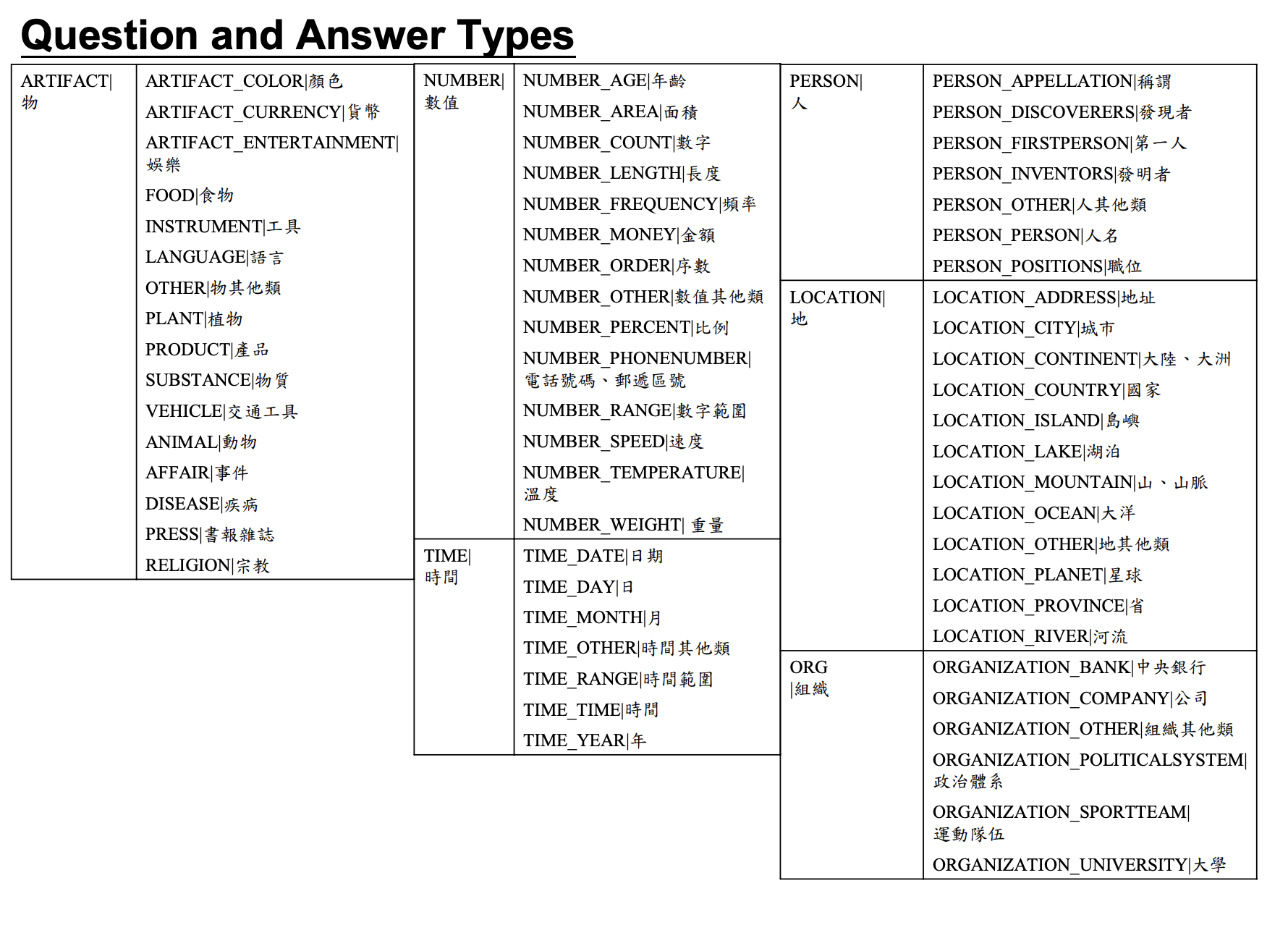
The dataset originally consists of 1216 pairs of question and question label, which first published by the author of this GitHub tim5go
There are 9 question types in total, namely:
- NUMBER
- PERSON
- LOCATION
- ORGANIZATION
- ARTIFACT
- TIME
- PROCEDURE
- AFFIRMATION
- CAUSALITY
Embedding Preparation
In my experiment, I built a word2vec model on 全網新聞數據(SogouCA) Sogou Labs
For example, in Linux:
- clean XML tag
$ cat news_tensite_xml.dat | iconv -f gbk -t utf-8 -c | grep "<content>"
| sed 's\<content>\\' | sed 's\</content>\\' > corpus.txt
- word segmentation using LTP command line
$ cws_cmdline --threads 4 --input corpus.txt --segmentor-model cws.model > corpus.seg.txt
- simplified to traditional Chinese conversion using OpenCC
$ opencc -i corpus.seg.txt -o corpus_trad.txt -c s2t.json
- word2Vec training using Google Word2vec
$ nohup ./word2vec -train corpus_trad.txt -output sogou_vectors.bin -cbow 0
-size 200 -window 10 -negative 5 -hs 0 -sample 1e-4 -threads 24 -binary 1 -iter 20 -min-count 1 &
Result
| Training Loss | Training Accuracy | Validation Loss | Validation Accuracy |
|---|---|---|---|
| 0.7000 | 87.11% | 0.8945 | 77.87% |
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].