akashmjn / Cs224n Gpu That Talks
Attention, I'm Trying to Speak: End-to-end speech synthesis (CS224n '18)
Stars: ✭ 52
Programming Languages
python3
1442 projects
Projects that are alternatives of or similar to Cs224n Gpu That Talks
Parallelwavegan
Unofficial Parallel WaveGAN (+ MelGAN & Multi-band MelGAN) with Pytorch
Stars: ✭ 682 (+1211.54%)
Mutual labels: jupyter-notebook, speech-synthesis, text-to-speech, tts
Pytorch Dc Tts
Text to Speech with PyTorch (English and Mongolian)
Stars: ✭ 122 (+134.62%)
Mutual labels: jupyter-notebook, speech-synthesis, text-to-speech, tts
Wavegrad
Implementation of Google Brain's WaveGrad high-fidelity vocoder (paper: https://arxiv.org/pdf/2009.00713.pdf). First implementation on GitHub.
Stars: ✭ 245 (+371.15%)
Mutual labels: jupyter-notebook, speech-synthesis, text-to-speech, tts
Tts
🐸💬 - a deep learning toolkit for Text-to-Speech, battle-tested in research and production
Stars: ✭ 305 (+486.54%)
Mutual labels: jupyter-notebook, text-to-speech, tts
editts
Official implementation of EdiTTS: Score-based Editing for Controllable Text-to-Speech
Stars: ✭ 74 (+42.31%)
Mutual labels: text-to-speech, tts, speech-synthesis
esp32-flite
Speech synthesis running on ESP32 based on Flite engine.
Stars: ✭ 28 (-46.15%)
Mutual labels: text-to-speech, tts, speech-synthesis
ttslearn
ttslearn: Library for Pythonで学ぶ音声合成 (Text-to-speech with Python)
Stars: ✭ 158 (+203.85%)
Mutual labels: text-to-speech, tts, speech-synthesis
Glow Tts
A Generative Flow for Text-to-Speech via Monotonic Alignment Search
Stars: ✭ 284 (+446.15%)
Mutual labels: speech-synthesis, text-to-speech, tts
Parakeet
PAddle PARAllel text-to-speech toolKIT (supporting WaveFlow, WaveNet, Transformer TTS and Tacotron2)
Stars: ✭ 279 (+436.54%)
Mutual labels: speech-synthesis, text-to-speech, tts
Voice Builder
An opensource text-to-speech (TTS) voice building tool
Stars: ✭ 362 (+596.15%)
Mutual labels: speech-synthesis, text-to-speech, tts
Lightspeech
LightSpeech: Lightweight and Fast Text to Speech with Neural Architecture Search
Stars: ✭ 31 (-40.38%)
Mutual labels: speech-synthesis, text-to-speech, tts
Fre-GAN-pytorch
Fre-GAN: Adversarial Frequency-consistent Audio Synthesis
Stars: ✭ 73 (+40.38%)
Mutual labels: text-to-speech, tts, speech-synthesis
spokestack-android
Extensible Android mobile voice framework: wakeword, ASR, NLU, and TTS. Easily add voice to any Android app!
Stars: ✭ 52 (+0%)
Mutual labels: text-to-speech, tts, speech-synthesis
Comprehensive-Tacotron2
PyTorch Implementation of Google's Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions. This implementation supports both single-, multi-speaker TTS and several techniques to enforce the robustness and efficiency of the model.
Stars: ✭ 22 (-57.69%)
Mutual labels: text-to-speech, tts, speech-synthesis
talkie
Text-to-speech browser extension button. Select text on any web page, and have the computer read it out loud for you by simply clicking the Talkie button.
Stars: ✭ 43 (-17.31%)
Mutual labels: text-to-speech, tts, speech-synthesis
Hifi Gan
HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
Stars: ✭ 325 (+525%)
Mutual labels: speech-synthesis, text-to-speech, tts
Jsut Lab
HTS-style full-context labels for JSUT v1.1
Stars: ✭ 28 (-46.15%)
Mutual labels: speech-synthesis, text-to-speech, tts
Tts
🤖 💬 Deep learning for Text to Speech (Discussion forum: https://discourse.mozilla.org/c/tts)
Stars: ✭ 5,427 (+10336.54%)
Mutual labels: jupyter-notebook, text-to-speech, tts
Parallel-Tacotron2
PyTorch Implementation of Google's Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Stars: ✭ 149 (+186.54%)
Mutual labels: text-to-speech, tts, speech-synthesis
LVCNet
LVCNet: Efficient Condition-Dependent Modeling Network for Waveform Generation
Stars: ✭ 67 (+28.85%)
Mutual labels: text-to-speech, tts, speech-synthesis
Attention, I'm Trying to Speak: End-to-end speech synthesis (CS224n '18)
Implementation of a convolutional seq2seq-based text-to-speech model based on Tachibana et. al. (2017). Given a sequence of characters, the model predicts a sequence of spectrogram frames in two stages (Text2Mel and SSRN).
As discussed in the report, we can get fairly decent audio quality with Text2Mel trained for 60k steps, SSRN for 100k steps. This corresponds to about (6+12) hours of training on a single Tesla K80 GPU on the LJ Speech Dataset.
Pretrained Model: [download]
Samples: [base-model-M4] [unsupervised-decoder-M1]
For more details see:
Poster Paper
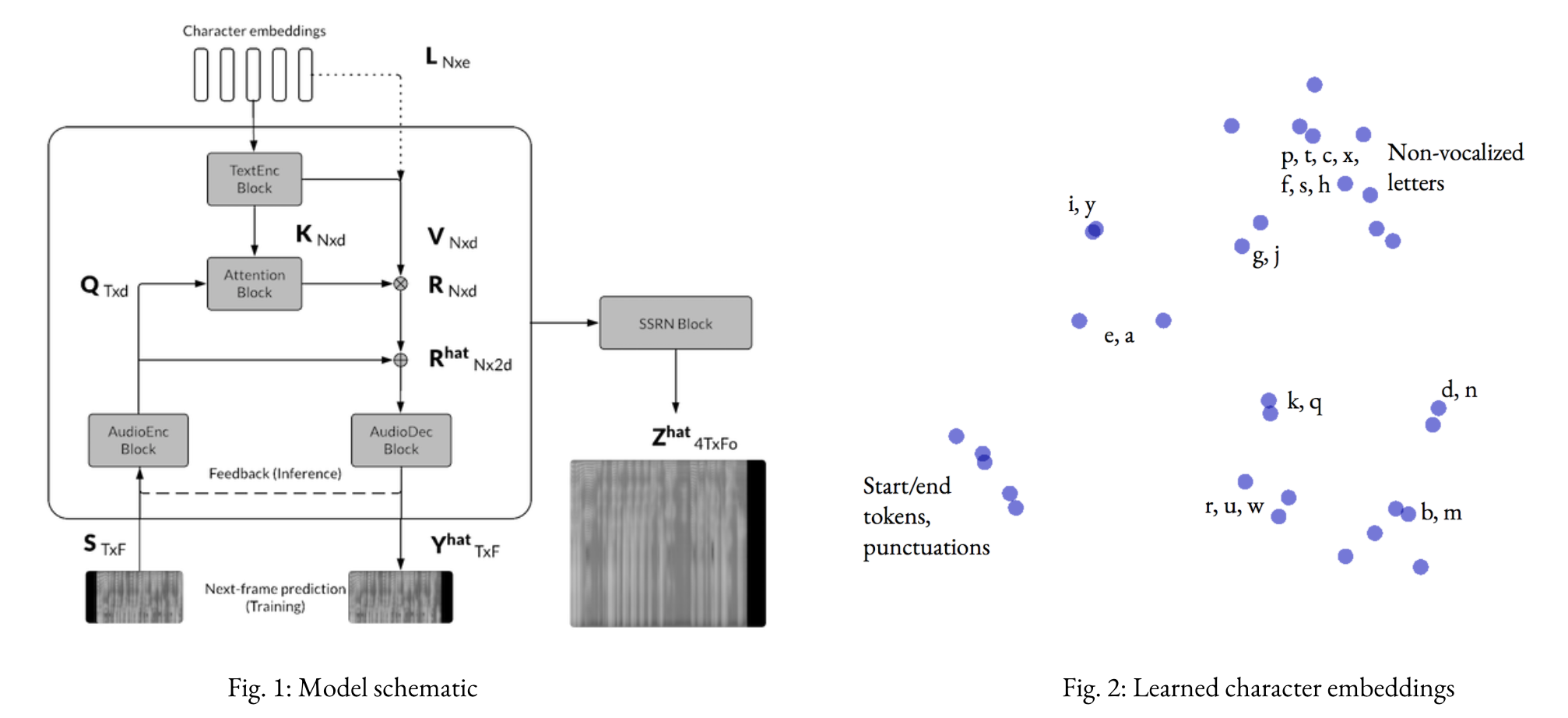
Usage:
Directory Structure
- runs (contains checkpoints and params.json file for each different run. params.json specifies various hyperameters: see params-examples folder)
- run1/params.json ...
- src (implementation code package)
- sentences (contains test sentences in .txt files)
train.py
evaluate.py
synthesize.py
../data (directory containing data in format below)
- FOLDER
- train.csv, val.csv (files containing [wav_file_name|transcript|normalized_trascript] as in LJ-Speech dataset)
- wavs (folder containing corresponding .wav audio files)
Script files
Run each file with python <script_file>.py -h to see usage details.
python train.py <PATH_PARAMS.JSON> <MODE>
python evaluate.py <PATH_PARAMS.JSON> <MODE>
python synthesize.py <TEXT2MEL_PARAMS> <SSRN_PARAMS> <SENTENCES.txt> (<N_ITER> <SAMPLE_DIR>)
Notebooks:
- Evaluation: Runs model predictions across the entire training and validation sets for different saved model checkpoints and saves the final results.
- Demo: Interactively type input sentences and listen to the generated output audio.
Further:
- Training on different languages with smaller amount of data available Dataset of Indian languages
- Exploring use of semi-supervised methods to accelerate training, using a pre-trained 'audio-language model' as initialization
Referenced External Code:
(From src/init.py) Utility Code has been referenced from the following sources, all other code is the author's own:
- src/data_load.py, dsp_utils.py (with modifications)
https://www.github.com/kyubyong/dc_tts, (Author: kyubyong park, @Kyubyong) https://github.com/r9y9/deepvoice3_pytorch/blob/master/audio.py (Author: @r9y9) - src/spsi.py (referenced)
https://github.com/lonce/SPSI_Python (Author: @lonce) - src/utils.py (referenced)
https://github.com/cs230-stanford/cs230-code-examples https://www.github.com/kyubyong/dc_tts https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/layers/common_attention.py
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].