目录结构
├─controller/ 请求接口目录
│ ├─elastic/ elasticsearch-php 操作类库
│ │
│ ├─api.php 请求接口
│ ├─custom_word.php 提供给es ik 远程更新的分词库url
│ └─setup_word.php 配置词库操作接口
│
├─crontab/ 运行脚本
│ └─sync_suggest_words.php 将热词库 同步到 suggest es index
│
├─words/ 存放词库文件夹
│ ├─hot/ 热词词库文件夹
│ │ ├─sougou.dic 搜狗热词库
│ │ ├─single_word_low_freq.dic 生僻字的单字词库
│ │ └─ ... 更多词库文件
│ │
│ ├─stop/ 屏蔽分词词库文件夹
│ │ ├─ext_stopword.dic 屏蔽词词库文件
│ │ └─ ... 更多屏蔽词词库文件
│ │
│ ├─backup/ 一些待用的词库(如果你需要分词搜索结果 不出现/不出现,那就把该文件放到stop/或者 hot/ 下)
│ │ ├─sougou.dic 搜狗热词库
│ │ ├─single_word_full.dic 完整的单字词库(如果你需要分词搜索结果不出现单字,那就把该文件放到stop/下)
│ │ ├─single_word.dic 常见单字的单字词库 (如果你需要分词搜索结果不出现单字,那就把该文件放到stop/下)
│ │ ├─single_word_low_freq.dic 生僻字的单字词库
│ │ └─ ... 更多词库文件
│
├─js/ js
├─common.php 公共函数
├─config.php 配置文件
└─analyzer.html demo页面
说明
一、es的ik分词插件支持远程热词和屏蔽词
二、尽量规避单个语气字的词汇出现
三、自定义分词的维护,es-ik插件支持远程词库
1、可自行设置自定义分词词汇,使用文件配置保存,提供远程访问库功能
2、提供自定义词汇、自定义规避词汇设置
3、es对远程词库支持热更,不需要重启服务,1分钟刷新一次
4、可自动更新,可根据需要找到合适的源,自动维护最新热词到自定义词库(这里是用了搜狗词库sougou.dic)
5、远程词库也用于 suggester
四、同一个index,同一字段只能设置一种分词器类型。需要切换分词器,只能冗余字段了。
五、输入的自动补全、纠错机制 suggester
es自带了一个suggester,可以使用。
六、同义词的映射的维护(备选)
1、有些场景需要搜索同义词,如:搜 ”周杰伦“ 可以出现他英文名 ”jay“ 的内容, 这个在suggester做更好
2、计划使用redis zset结构保存对应关系,如果suggester的几种机制能满足就更好了
3、首先使用分词操作,将语句分词,再对每个分词查找他们的对应关系
比如{"text":"burn罗玉凤”} 拆词应该是 burn 罗玉凤,
罗玉凤:使用自定义分词维护, 凰:是burn的映射同义词, 为了避免同义词追加后与原查询语句干扰(避免分出“凤凰”),用“-” 分割
{"text":"burn罗玉凤-凰”}
(希望可以在网上找到词库,进行自动维护)
七、个人觉得好的全文搜索引擎,最重要的还是有个不断维护的完善的词库。
八、精髓还是搜索框的输入补全,多种模式互补,具体看自身需求
开始为了快速写个demo用了php,随着开发,其实用python、或者go更好...
end... 抽空继续完善中....
安装和使用
1、环境安装
es(5.3.0) 和 ik插件(5.3.0)的安装启动过程比较简单跳过。
es安装启动主要注意的问题是:文件夹权限、ulimit数量、JVM配置优化
ik插件可直接下载包放到: $elasticsearch/plugins/ik/ 下。 也可以直接插件命令行安装: $plugin —install analysis-ik
需要注意的是ik的版本需要和elasticsearch 完全对应
2、测试分词器
ik 带有两个分词器:
ik_max_word :会将文本做最细粒度的拆分;尽可能多的拆分出词语
ik_smart:会做最粗粒度的拆分;已被分出的词语将不会再次被其它词语占有
curl -XGET 'http://localhost:9200/_analyze?pretty&analyzer=ik_max_word' -d '一师是个好学校'
curl -XGET 'http://localhost:9200/_analyze?pretty&analyzer=ik_smart' -d '一师是个好学校'
3、配置远程词库
$vim elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">custom/mydict.dic;custom/single_word_low_freq.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">custom/ext_stopword.dic</entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://demo.liukelin.top/elastic-search-analyzer/controller/custom_word.php?action=hot</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">http://demo.liukelin.top/elastic-search-analyzer/controller/custom_word.php?action=stop</entry> -->
</properties>
参考内容:
$s = <<<'EOF'
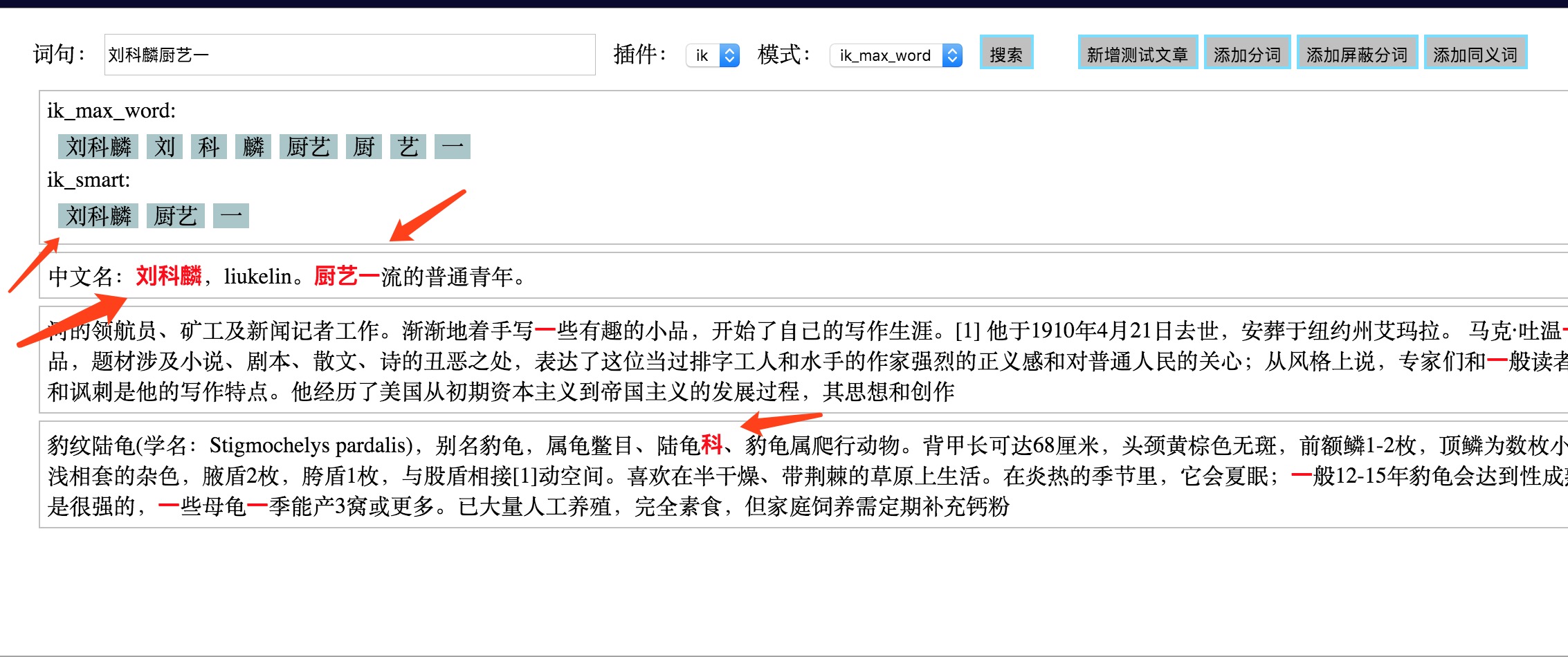
刘科麟
liukelin
EOF;
header('Last-Modified: '.gmdate('D, d M Y H:i:s', time()).' GMT', true, 200);
header('ETag: "5816f349-19"');
exit($s);
一行一个词 ik 接收两个返回的头部属性 Last-Modified 和 ETag,只要其中一个有变化,就会触发更新,ik 会每分钟获取一次
现在的项目是用去搜狗输入法官网的热词来更新最新词汇
4、index分词器设置
(index同字段只能设置一种分词模式)
创建index,并设置分词类型, 这里index: ik-test, doc_type: ik-test-doc, 分词器: ik_max_word, 字段: content
curl -XPUT http://localhost:9200/ik-test/ -d
'{
"settings": {
"analysis": {
"analyzer": {
"ik": {
"tokenizer": "ik_max_word"
}
}
}
},
"mappings": {
"ik-test-doc": { // doc_type
"dynamic": true,
"properties": {
"content": { //字段
"type": "string", //类型
"analyzer": "ik_max_word", //分词类型
"store": "no",
"term_vector": "with_positions_offsets",
"search_analyzer": "ik_max_word",
"include_in_all": "true",
"boost": 1
}
}
}
}
}'
(其他参数作用还不明,后续补充)
5、插入测试数据
curl -XPOST http://localhost:9200/ik-test/ik-test-doc/ -d
'{ "content": "一师是个好学校" }'
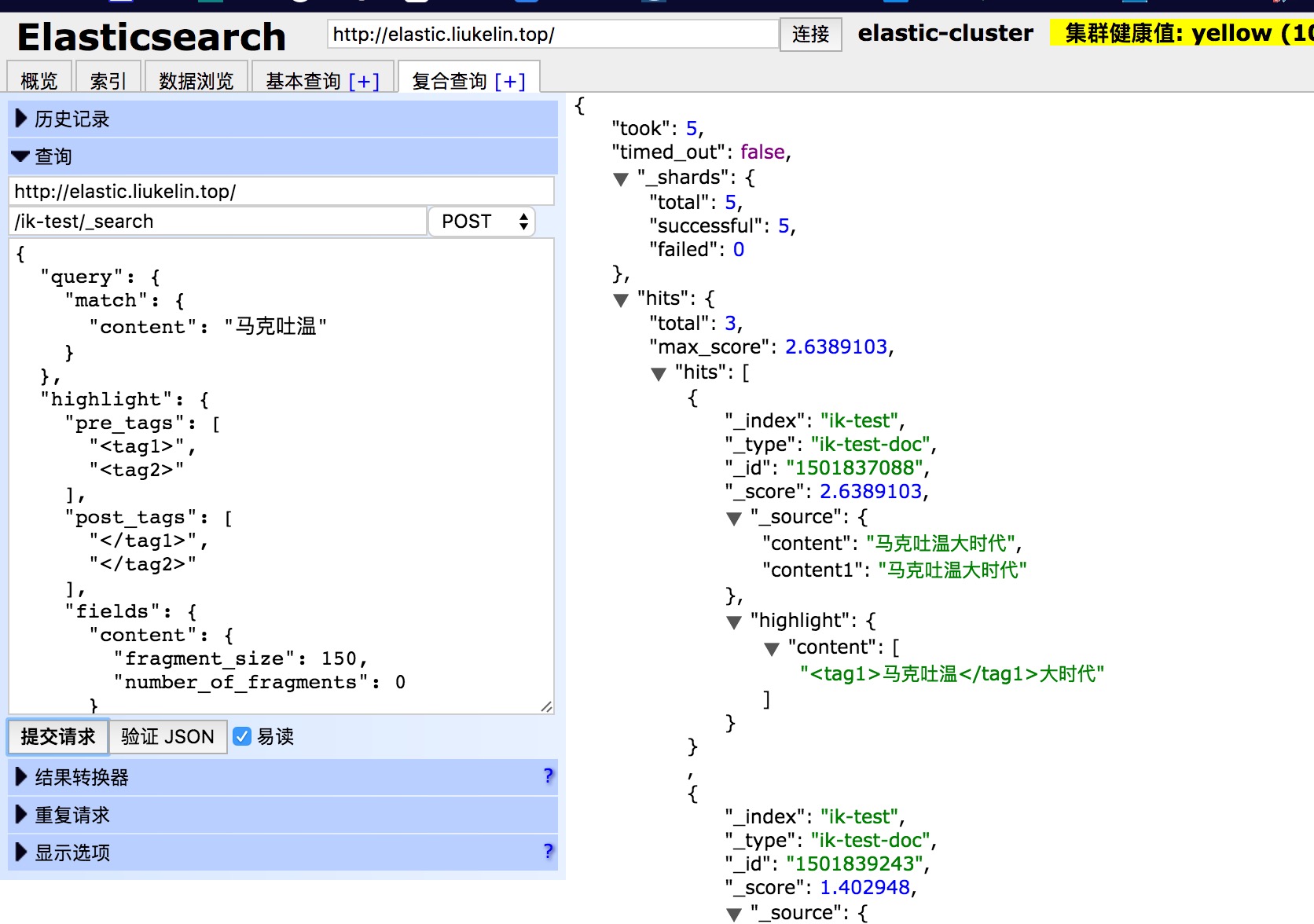
6、测试搜索分词
curl -XPOST http://localhost:9200/ik-test/_search/ -d
'{
"query" : {
"match" : {
"content" : "一师是个好学校" // 需要搜索的 字段:内容
}
},
"highlight" : { // 搜索结果配置
"pre_tags" : ["<tag1>", "<tag2>"], // 匹配高亮标签
"post_tags": ["</tag1>", "</tag2>"], // 匹配高亮结束标签
"fields" : {
"content" : { // 搜索结果字段 配置
"fragment_size" : 150, // 高亮显示的字符片段大小
"number_of_fragments" : 0, // 以及返回的最大片段数
#"order":0 // 设置为score时候可以按照评分进行排序
}
}
}
}'
end...
自定义分词:
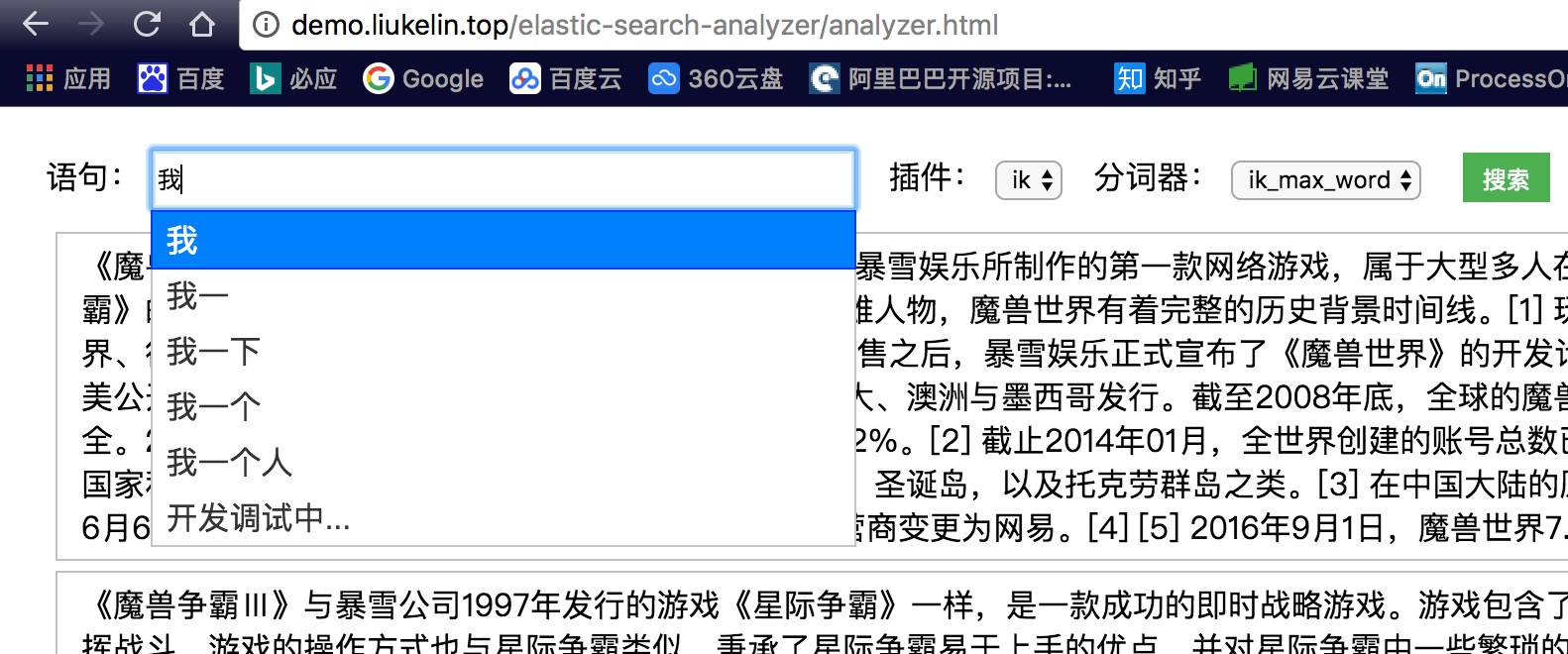
7、输入搜索建议 Suggesters API
Suggesters基本的运作原理是将输入的文本分解为token,然后在索引的字典里查找相似的term并返回。
根据使用场景的不同,Elasticsearch里设计了4种类别的 Suggester ,分别是:
Term Suggester
Phrase Suggester
Completion Suggester
Context Suggester
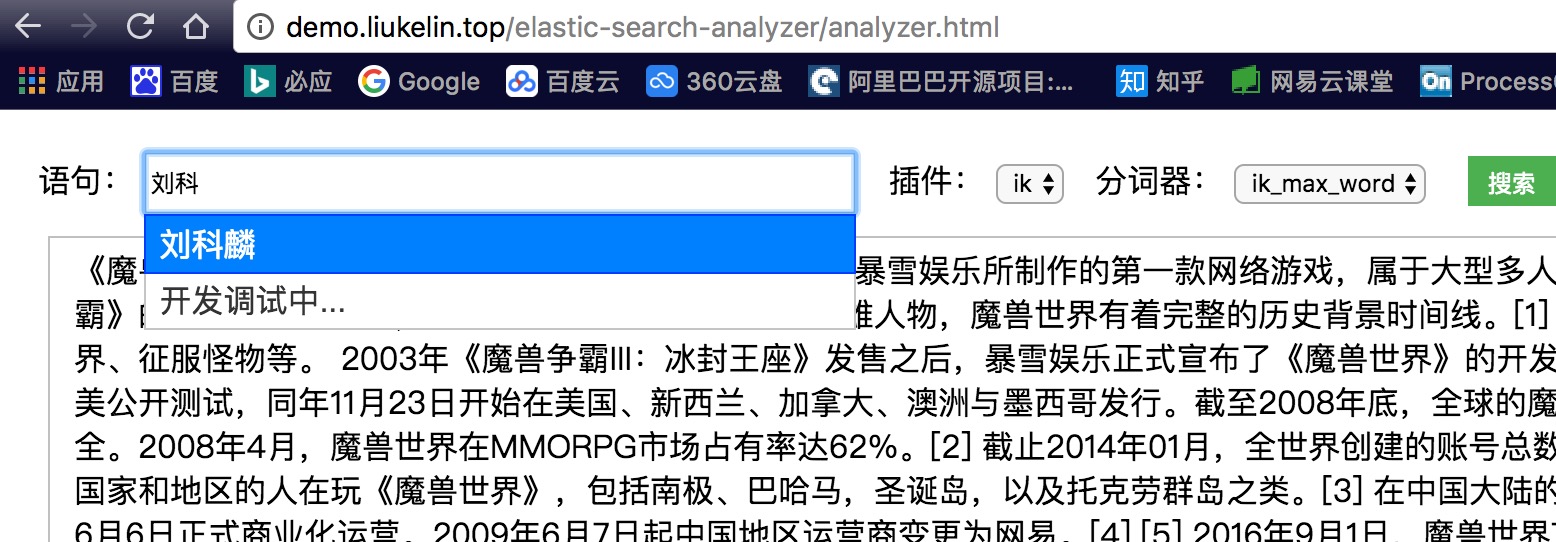
1、将使用的远程词库导入到 Suggester 作为搜索建议词库
2、创建 Completion 来作为前缀补全
3、如果前缀补全无法匹配到,则尝试用 Term - analyzer 分词匹配(有点类似于纠错了)
4、对于较长长的输入,可优先使用分词纠错 再 Completion
5、或者根据 同音 词纠错 再 Completion(待定)
6、... 其他策略待定
Suggesters API官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters.html
demo地址:
https://demo.liukelin.top/elastic-search-analyzer/analyzer.html