Code has been run on Google Colab, thanks Google for providing computational resources
Contents
-
Natural Language Processing(自然语言处理)
-
-
IMDB(ENG)
-
CLUE Emotion Analysis Dataset (CHN)
-
-
-
SNLI(ENG)
-
微众银行智能客服(CHN)
-
蚂蚁金融语义相似度 (CHN)
-
-
Intent Detection and Slot Filling(意图检测与槽位填充)
- ATIS(ENG)
-
-
ElasticSearch
-
Sparse Retrieval
-
Dense Retrieval
-
-
-
- Large-scale Chinese Conversation Dataset (CHN)
-
Multi-turn Dialogue Rewriting(多轮对话改写)
- 20k 腾讯 AI 研发数据(CHN)
-
- Facebook's Hierarchical Task Oriented Dialog(ENG)
-
Multi-hop Question Answering(多跳问题回答)
- bAbI(ENG)
-
-
Topic Modelling
-
Explain Prediction
-
-
-
Knowledge Graph(知识图谱)
-
- Movielens 1M(English Data)
Text Classification
└── finch/tensorflow2/text_classification/imdb
│
├── data
│ └── glove.840B.300d.txt # pretrained embedding, download and put here
│ └── make_data.ipynb # step 1. make data and vocab: train.txt, test.txt, word.txt
│ └── train.txt # incomplete sample, format <label, text> separated by \t
│ └── test.txt # incomplete sample, format <label, text> separated by \t
│ └── train_bt_part1.txt # (back-translated) incomplete sample, format <label, text> separated by \t
│
├── vocab
│ └── word.txt # incomplete sample, list of words in vocabulary
│
└── main
└── sliced_rnn.ipynb # step 2: train and evaluate model
└── ...
-
Task: IMDB(English Data)
Training Data: 25000, Testing Data: 25000, Labels: 2-
<Notebook>: Make Data & Vocabulary
Back-Translation increases training data from 25000 to 50000 which is done by "english -> french -> english" translation -
Model: TF-IDF + Logistic Regression (Sklearn)
Logistic Regression Binary TF NGram Range Knowledge Dist Testing Accuracy <Notebook> False (1, 1) False 88.3% <Notebook> True (1, 1) False 88.8% <Notebook> True (1, 2) False 89.6% <Notebook> True (1, 2) True 90.7% -> PySpark Equivalent
-
Model: FastText, CNN and RNN
Code Model Testing Accuracy <Notebook> FastText (Unigram) 87.3% <Notebook> FastText (Bigram) 89.8% <Notebook> FastText (AutoTune) 90.1% <Notebook> TextCNN 91.8% <Notebook> Sliced RNN 92.6% -
Model: Large-scale Transformer
-
TensorFlow 2 + transformers
Code Model Batch Size Max Length Testing Accuracy <Notebook> BERT 32 128 92.6% <Notebook> BERT 16 200 93.3% <Notebook> BERT 12 256 93.8% <Notebook> BERT 8 300 94% <Notebook> RoBERTa 8 300 94.7%
-
-
└── finch/tensorflow2/text_classification/clue
│
├── data
│ └── make_data.ipynb # step 1. make data and vocab
│ └── train.txt # download from clue benchmark
│ └── test.txt # download from clue benchmark
│
├── vocab
│ └── label.txt # list of emotion labels
│
└── main
└── bert_finetune.ipynb # step 2: train and evaluate model
└── ...
-
Task: CLUE Emotion Analysis Dataset(Chinese Data)
Training Data: 31728, Testing Data: 3967, Labels: 7-
Model: TF-IDF + Linear Model
Logistic Regression Binary TF NGram Range Split By Testing Accuracy <Notebook> False (1, 1) Char 57.4% <Notebook> True (1, 1) Word 57.7% <Notebook> False (1, 2) Word 57.8% <Notebook> False (1, 1) Word 58.3% <Notebook> True (1, 2) Char 59.1% <Notebook> False (1, 2) Char 59.4% -
Model: Deep Model
Code Model Env Testing Accuracy <Notebook> BERT TF2 61.7% <Notebook> BERT + TAPT (<Notebook>) TF2 62.3%
-
Text Matching
└── finch/tensorflow2/text_matching/snli
│
├── data
│ └── glove.840B.300d.txt # pretrained embedding, download and put here
│ └── download_data.ipynb # step 1. run this to download snli dataset
│ └── make_data.ipynb # step 2. run this to generate train.txt, test.txt, word.txt
│ └── train.txt # incomplete sample, format <label, text1, text2> separated by \t
│ └── test.txt # incomplete sample, format <label, text1, text2> separated by \t
│
├── vocab
│ └── word.txt # incomplete sample, list of words in vocabulary
│
└── main
└── dam.ipynb # step 3. train and evaluate model
└── esim.ipynb # step 3. train and evaluate model
└── ......
-
Task: SNLI(English Data)
Training Data: 550152, Testing Data: 10000, Labels: 3Code Reference Env Testing Accuracy <Notebook> DAM TF2 85.3% <Notebook> Match Pyramid TF2 87.1% <Notebook> ESIM TF2 87.4% <Notebook> RE2 TF2 87.7% <Notebook> RE3 TF2 88.3% <Notebook> BERT TF2 90.4% <Notebook> RoBERTa TF2 91.1%
└── finch/tensorflow2/text_matching/chinese
│
├── data
│ └── make_data.ipynb # step 1. run this to generate char.txt and char.npy
│ └── train.csv # incomplete sample, format <text1, text2, label> separated by comma
│ └── test.csv # incomplete sample, format <text1, text2, label> separated by comma
│
├── vocab
│ └── cc.zh.300.vec # pretrained embedding, download and put here
│ └── char.txt # incomplete sample, list of chinese characters
│ └── char.npy # saved pretrained embedding matrix for this task
│
└── main
└── pyramid.ipynb # step 2. train and evaluate model
└── esim.ipynb # step 2. train and evaluate model
└── ......
-
Task: 微众银行智能客服(Chinese Data)
Training Data: 100000, Testing Data: 10000, Labels: 2, Balanced-
Model (can be compared to this benchmark since the dataset is the same)
Code Reference Env Split by Testing Accuracy <Notebook> RE2 TF2 Word 82.5% <Notebook> ESIM TF2 Char 82.5% <Notebook> Match Pyramid TF2 Char 82.7% <Notebook> RE2 TF2 Char 83.8% <Notebook> BERT TF2 Char 83.8% <Notebook> BERT-wwm TF1 + bert4keras Char 84.75%
└── finch/tensorflow2/text_matching/ant
│
├── data
│ └── make_data.ipynb # step 1. run this to generate char.txt and char.npy
│ └── train.json # incomplete sample, format <text1, text2, label> separated by comma
│ └── dev.json # incomplete sample, format <text1, text2, label> separated by comma
│
├── vocab
│ └── cc.zh.300.vec # pretrained embedding, download and put here
│ └── char.txt # incomplete sample, list of chinese characters
│ └── char.npy # saved pretrained embedding matrix for this task
│
└── main
└── pyramid.ipynb # step 2. train and evaluate model
└── bert.ipynb # step 2. train and evaluate model
└── ......
-
Task: 蚂蚁金融语义相似度(Chinese Data)
Training Data: 34334, Testing Data: 4316, Labels: 2, ImbalancedCode Reference Env Split by Testing Accuracy <Notebook> RE2 TF2 Char 66.5% <Notebook> Match Pyramid TF2 Char 69.0% <Notebook> Match Pyramid + Joint Training TF2 Char 70.3% <Notebook> BERT TF2 Char 73.8% <Notebook> BERT + TAPT (<Notebook>) TF2 Char 74.3% -
Joint training
-
set data_1 = 微众银行智能客服 (size: 100000)
-
set data_2 = 蚂蚁金融语义相似度 (size: 34334)
-
joint training (size: 100000 + 34334 = 134334)
BERT train by data_1 train by data_2 joint train joint train + TAPT Code <Notebook> <Notebook> <Notebook> <Notebook> data_1 accuracy 83.8% - 84.4% 85.0% data_2 accuracy - 73.8% 74.0% 74.9% -
Intent Detection and Slot Filling
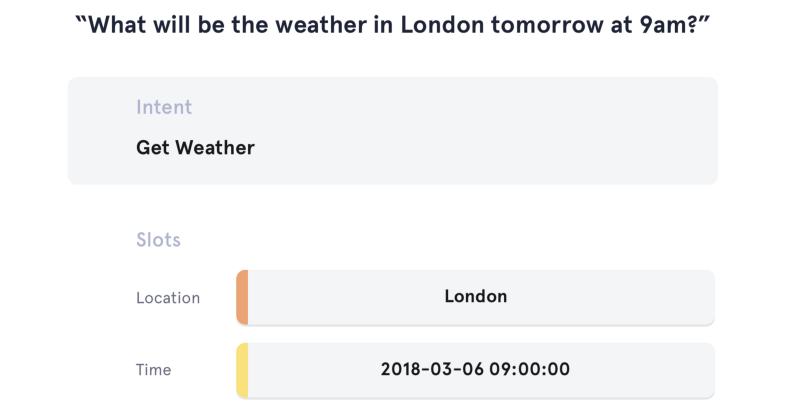
└── finch/tensorflow2/spoken_language_understanding/atis
│
├── data
│ └── glove.840B.300d.txt # pretrained embedding, download and put here
│ └── make_data.ipynb # step 1. run this to generate vocab: word.txt, intent.txt, slot.txt
│ └── atis.train.w-intent.iob # incomplete sample, format <text, slot, intent>
│ └── atis.test.w-intent.iob # incomplete sample, format <text, slot, intent>
│
├── vocab
│ └── word.txt # list of words in vocabulary
│ └── intent.txt # list of intents in vocabulary
│ └── slot.txt # list of slots in vocabulary
│
└── main
└── bigru_clr.ipynb # step 2. train and evaluate model
└── ...
-
Task: ATIS(English Data)
Training Data: 4978, Testing Data: 893Code Model Helper Env Intent Accuracy Slot Micro-F1 <Notebook> CRF - crfsuite - 92.6% <Notebook> Bi-GRU - TF2 97.4% 95.4% <Notebook> Bi-GRU + CRF TF2 97.2% 95.8% <Notebook> Transformer - TF2 96.5% 95.5% <Notebook> Transformer + Time Weighting TF2 97.2% 95.6% <Notebook> Transformer + Time Mixing TF2 97.5% 95.8% <Notebook> Bi-GRU + ELMO TF1 97.5% 96.1% <Notebook> Bi-GRU + ELMO + CRF TF1 97.3% 96.3%
Retrieval Dialog
-
Task: Build a chatbot answering fundamental questions
Code Engine Encoder Vector Type Unit Test Accuracy <Notebook> Elastic Search Default (TF-IDF) Sparse 80% <Notebook> Elastic Search Default (TF-IDF) + Segmentation Sparse 90% <Notebook> Elastic Search Bert Dense 80% <Notebook> Elastic Search Universal Sentence Encoder Dense 100%
Semantic Parsing
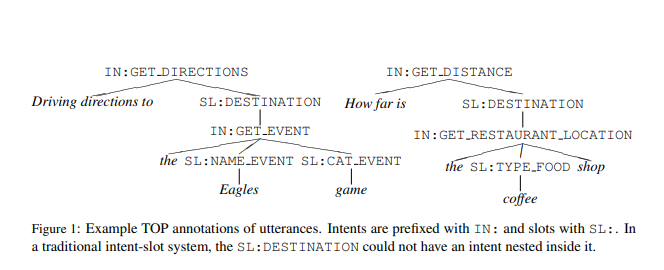
└── finch/tensorflow2/semantic_parsing/tree_slu
│
├── data
│ └── glove.840B.300d.txt # pretrained embedding, download and put here
│ └── make_data.ipynb # step 1. run this to generate vocab: word.txt, intent.txt, slot.txt
│ └── train.tsv # incomplete sample, format <text, tokenized_text, tree>
│ └── test.tsv # incomplete sample, format <text, tokenized_text, tree>
│
├── vocab
│ └── source.txt # list of words in vocabulary for source (of seq2seq)
│ └── target.txt # list of words in vocabulary for target (of seq2seq)
│
└── main
└── lstm_seq2seq_tf_addons.ipynb # step 2. train and evaluate model
└── ......
-
Task: Semantic Parsing for Task Oriented Dialog(English Data)
Training Data: 31279, Testing Data: 9042Code Reference Env Testing Exact Match <Notebook> GRU Seq2Seq TF2 74.1% <Notebook> LSTM Seq2Seq TF2 74.1% <Notebook> GRU Pointer-Generator TF2 80.4% <Notebook> GRU Pointer-Generator + Char Embedding TF2 80.7% The Exact Match result is higher than original paper
Knowledge Graph Completion
└── finch/tensorflow2/knowledge_graph_completion/wn18
│
├── data
│ └── download_data.ipynb # step 1. run this to download wn18 dataset
│ └── make_data.ipynb # step 2. run this to generate vocabulary: entity.txt, relation.txt
│ └── wn18 # wn18 folder (will be auto created by download_data.ipynb)
│ └── train.txt # incomplete sample, format <entity1, relation, entity2> separated by \t
│ └── valid.txt # incomplete sample, format <entity1, relation, entity2> separated by \t
│ └── test.txt # incomplete sample, format <entity1, relation, entity2> separated by \t
│
├── vocab
│ └── entity.txt # incomplete sample, list of entities in vocabulary
│ └── relation.txt # incomplete sample, list of relations in vocabulary
│
└── main
└── distmult_1-N.ipynb # step 3. train and evaluate model
└── ...
-
Task: WN18
Training Data: 141442, Testing Data: 5000-
We use the idea of multi-label classification to accelerate evaluation
Code Reference Env MRR Hits@10 Hits@3 Hits@1 <Notebook> DistMult TF2 0.797 0.938 0.902 0.688 <Notebook> TuckER TF2 0.885 0.939 0.909 0.853 <Notebook> ComplEx TF2 0.938 0.958 0.948 0.925
Knowledge Base Question Answering

-
Rule-based System(基于规则的系统)
For example, we want to answer the following questions with car knowledge:
What is BMW? I want to know about the BMW Please introduce the BMW to me How is the BMW? How is the BMW compared to the Benz?
Multi-hop Question Answering

└── finch/tensorflow1/question_answering/babi
│
├── data
│ └── make_data.ipynb # step 1. run this to generate vocabulary: word.txt
│ └── qa5_three-arg-relations_train.txt # one complete example of babi dataset
│ └── qa5_three-arg-relations_test.txt # one complete example of babi dataset
│
├── vocab
│ └── word.txt # complete list of words in vocabulary
│
└── main
└── dmn_train.ipynb
└── dmn_serve.ipynb
└── attn_gru_cell.py
-
Task: bAbI(English Data)
Text Visualization
-
Topic Modelling
-
Model: TF-IDF + LDA
-
Data: IMDB Movie Reviews
-
-
Explain Prediction
-
Model: SHAP
-
Data: IMDB Movie Reviews
-
Recommender System

└── finch/tensorflow1/recommender/movielens
│
├── data
│ └── make_data.ipynb # run this to generate vocabulary
│
├── vocab
│ └── user_job.txt
│ └── user_id.txt
│ └── user_gender.txt
│ └── user_age.txt
│ └── movie_types.txt
│ └── movie_title.txt
│ └── movie_id.txt
│
└── main
└── dnn_softmax.ipynb
└── ......
-
Task: Movielens 1M(English Data)
Training Data: 900228, Testing Data: 99981, Users: 6000, Movies: 4000, Rating: 1-5-
Model: Fusion
Code Scoring LR Decay Env Testing MAE <Notebook> Sigmoid (Continuous) Exponential TF1 0.663 <Notebook> Sigmoid (Continuous) Cyclical TF1 0.661 <Notebook> Softmax (Discrete) Exponential TF1 0.633 <Notebook> Softmax (Discrete) Cyclical TF1 0.628 The MAE results seem better than the all the results here and all the results here
Multi-turn Dialogue Rewriting

└── finch/tensorflow1/multi_turn_rewrite/chinese/
│
├── data
│ └── make_data.ipynb # run this to generate vocab, split train & test data, make pretrained embedding
│ └── corpus.txt # original data downloaded from external
│ └── train_pos.txt # processed positive training data after {make_data.ipynb}
│ └── train_neg.txt # processed negative training data after {make_data.ipynb}
│ └── test_pos.txt # processed positive testing data after {make_data.ipynb}
│ └── test_neg.txt # processed negative testing data after {make_data.ipynb}
│
├── vocab
│ └── cc.zh.300.vec # fastText pretrained embedding downloaded from external
│ └── char.npy # chinese characters and their embedding values (300 dim)
│ └── char.txt # list of chinese characters used in this project
│
└── main
└── baseline_lstm_train.ipynb
└── baseline_lstm_predict.ipynb
└── ...
-
Task: 20k 腾讯 AI 研发数据(Chinese Data)
data split as: training data (positive): 18986, testing data (positive): 1008 Training data = 2 * 18986 because of 1:1 Negative Sampling-
<Notebook>: Make Data & Vocabulary & Pretrained Embedding
There are six incorrect data and we have deleted them -
Model (results can be compared to here with the same dataset)
Code Model Env Exact Match BLEU-1 BLEU-2 BLEU-4 <Notebook> LSTM Seq2Seq + Dynamic Memory TF1 56.2% 94.6 89.1 78.5 <Notebook> GRU Seq2Seq + Dynamic Memory TF1 56.2% 95.0 89.5 78.9 <Notebook> GRU Pointer TF1 59.2% 93.2 87.7 77.2 <Notebook> GRU Pointer + Multi-Attention TF1 60.2% 94.2 88.7 78.3 -
Deployment: first export the model
Inference Code Environment <Notebook> Python <Notebook> Java
Generative Dialog
└── finch/tensorflow1/free_chat/chinese_lccc
│
├── data
│ └── LCCC-base.json # raw data downloaded from external
│ └── LCCC-base_test.json # raw data downloaded from external
│ └── make_data.ipynb # step 1. run this to generate vocab {char.txt} and data {train.txt & test.txt}
│ └── train.txt # processed text file generated by {make_data.ipynb}
│ └── test.txt # processed text file generated by {make_data.ipynb}
│
├── vocab
│ └── char.txt # list of chars in vocabulary for chinese
│ └── cc.zh.300.vec # fastText pretrained embedding downloaded from external
│ └── char.npy # chinese characters and their embedding values (300 dim)
│
└── main
└── lstm_seq2seq_train.ipynb # step 2. train and evaluate model
└── lstm_seq2seq_infer.ipynb # step 4. model inference
└── ...
-
Task: Large-scale Chinese Conversation Dataset
Training Data: 5000000 (sampled due to small memory), Testing Data: 19008-
Data
-
Model
Code Model Env Test Case Perplexity <Notebook> Transformer Encoder + LSTM Generator TF1 <Notebook> 42.465 <Notebook> LSTM Encoder + LSTM Generator TF1 <Notebook> 41.250 <Notebook> LSTM Encoder + LSTM Pointer-Generator TF1 <Notebook> 36.525 -
If you want to deploy model in Java production
└── FreeChatInference │ ├── data │ └── transformer_export/ │ └── char.txt │ └── libtensorflow-1.14.0.jar │ └── tensorflow_jni.dll │ └── src └── ModelInference.java-
If you don't know the input and output node names in Java, you can display the node names:
!saved_model_cli show --dir ../model/xxx/1587959473/ --tag_set serve --signature_def serving_default
-
Large Pre-trained GPT
Test Case Model Env Author <Notebook> GPT LCCC base TF1 + bert4keras Tsinghua University <Notebook> GPT LCCC large TF1 + bert4keras Tsinghua University <Notebook> NEZHA LM TF1 + bert4keras Jianlin Su -
Diverse Response Comparsion
问题 / 模型回复 Our RNN GPT base GPT large Nezha Q: 你好 A: 你好 A: 你好 A: 你好,你好,我是大好人。 A: 您好 Q: 早上好 A: 早上好 A: 早上好,好久不见 A: 早上好! A: 早啊早啊 Q: 晚上好 A: 晚上好 A: 你好 A: 好久不见 A: 晚上好! Q: 再见 A: 再见 A: 不见 A: 你是不是不爱我了 A: 我要走了 Q: 好久不见 A: 好久不见 A: 是呀,好久不见。 A: 是啊,好久不见。 A: 是啊,最近怎么样啊 Q: 想死你了 A: 我也是 A: 我也想你, A: 我不信 A: 哈哈哈哈哈 Q: 谢谢你 A: 不客气 A: 不用谢 A: 不用 A: 不谢不谢, Q: 爱你 A: 爱你 A: 你是爱我 A: 我也爱你, A: 我也爱你,你最美 Q: 你叫什么名字 A: 你猜 A: 我也想知道 A: 叫你 A: 你是不是想说我的名字太俗了 Q: 你几岁了 A: 问女孩子年龄可不是绅士所为哦 ~ A: 你猜 A: 你猜 A: 我不知道 Q: 现在几点了 A: 11点 A: 你说呢? A: 十二点 A: 我也不知道啊 Q: 今天天气怎么样 A: 下雨了 A: 今天很冷,但是我还是觉得很冷 A: 很好 A: 不错 Q: 我们现在在哪里 A: 在这里 A: 我在这里等你呢 A: 我不知道你在说什么 A: 在我们宿舍楼下。。。 Q: 你能给我讲个笑话吗 A: 不能 A: 讲个笑话 A: 讲给谁听 A: 不能 Q: 你是男孩还是女孩呀 A: 我是萌妹纸 A: 你猜 A: 你猜呀 A: 我是萌妹纸 Q: 你会几种语言呀 A: 你猜 A: 不会 A: 你猜呀~ A: 只会说一句 Q: 你能陪我玩吗 A: 可以啊 A: 可以 A: 我可以啊 A: 你猜 Q: 说话可以大声一点吗 A: 可以 A: 可以的 A: 不要 A: 我不 Q: 天气真好 A: 是的 A: 是啊! A: 天气好是因为有你 A: 是啊。 Q: 天气太糟糕了 A: 是啊 A: 是啊 A: 是啊 A: 是的 Q: 下雨了 A: 是的 A: 你们那边也下雨了 A: 是呀 A: 我也是 Q: 雨好大 A: 今天下雨了 A: 是啊 A: 是的,好大雨 A: 对呀,我们还穿短袖 Q: 我讨厌艳阳天 A: 我也讨厌艳阳天 A: 我也是。 A: 我喜欢阴天 A: 我喜欢 Q: 好晒啊 A: 是啊 A: 是啊 A: 是啊!! A: 是啊,不是很热的 Q: 今天好冷 A: 多穿点衣服 A: 你们都不来 A: 你那儿也冷了 A: 是啊。 Q: 今天好热 A: 今天热死了 A: 热死我了 A: 对啊 A: 对啊,我都热疯 Q: 风好大 A: 是啊 A: 风太大了。。。 A: 你不是在上课嘛 A: 嗯嗯嗯,风好大,冷 Q: 雾太大了看不清路 A: 雾太大了 A: 哈哈,你这是在逗我笑 A: 我也看不清 A: 你是不是傻啊 Q: 打雷了好可怕 A: 可怕 A: 我们这边也是,我们这边下雨了,我们这边也没有下雨。 A: 是啊 A: 我们这边下雨了 Q: 下雪了诶 A: 下雪了? A: 是滴! A: 嗯嗯嗯!!好大的雪!! A: 下了一天了 Q: 好烦啊 A: 我也好烦 A: 我也是 A: 我好烦 A: 我也是 Q: 好开心 A: 开心就好 A: 你是不是想我了 A: 是呀 A: 哈哈哈,我也是! Q: 太激动了 A: 激动什么 A: 我也激动 A: 哈哈,还是不要了 A: 哈哈 Q: 我好难过 A: 怎么了? A: 我也是,我们都是 A: 不要难过,我陪你 A: 你怎么难过 Q: 我想哭 A: 抱抱 A: 抱紧你 A: 我不想哭!你不要想太多! A: 哭吧哭吧,我陪你哭 Q: 太好笑了 A: 笑死我了 A: 你也笑了? A: 我也觉得 A: 哈哈 Q: 我好伤心 A: 怎么了 A: 你伤心什么 A: 我也是 A: 你是不是想笑死我!!下次再给你拍 Q: 心好痛 A: 抱抱 A: 你心痛什么 A: 心碎一地了。 A: 怎么了 Q: 好累啊 A: 加油 A: 你不会还是一个人在寝室吧 A: 好好休息 A: 累了就睡觉 Q: 我好疲惫 A: 我也是 A: 我也差不多。。 A: 我好困 A: 你不是一直都很疲惫么 Q: 我爱你 A: 我也爱你 A: 我也是 A: 我们都爱你 A: 爱我就来见面 Q: 我讨厌你 A: 我也讨厌你 A: 你不是一直很喜欢我 A: 不是我的 A: 我也讨厌你 Q: 你真是太棒啦 A: 谢谢 A: 你最棒 A: 你也棒棒哒 A: 谢谢! Q: 你好厉害啊 A: 哈哈 A: 是不是 A: 你也不差呀 A: 你也可以的 Q: 吓死我了 A: 哈哈 A: 我都不敢出门了 A: 哈哈哈哈哈!!! A: 哈哈哈哈哈笑死我了 Q: 我想回家 A: 我也想回家 A: 我也想!! A: 想家的时候回来,想家的时候离开。 A: 回来吧,家真的好啊! Q: 我想爸妈了 A: 我也想爸妈 A: 哈哈 A: 我也想 A: 想我吗 Q: 不知道小孩在家有没有听话 A: 我也不知道 A: 没有 A: 听话的话肯定是会听话的。 A: 我也是听不懂啊 Q: 想回家撸猫 A: 我也想回家 A: 你也想啊? A: 我们这也有一个 A: 回呀回呀
-