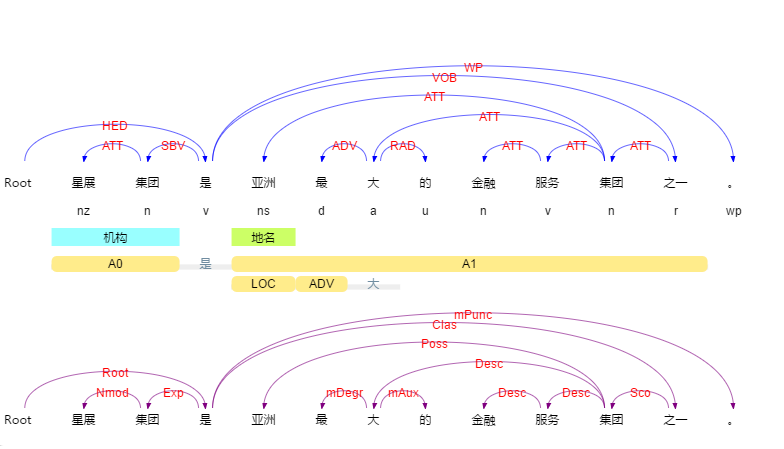
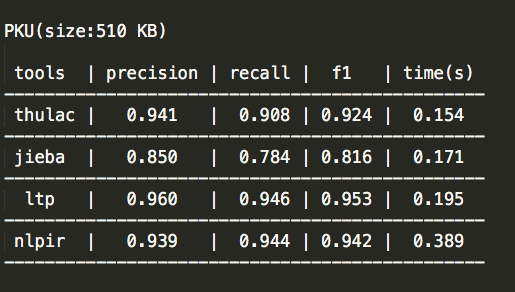
Segmentit任何 JS 环境可用的中文分词包,fork from leizongmin/node-segment
Stars: ✭ 139 (+41.84%)
Mutual labels: chinese, chinese-nlp
chinese-nlp-ner一套针对中文实体识别的BLSTM-CRF解决方案
Stars: ✭ 14 (-85.71%)
Mutual labels: chinese, chinese-nlp
Pytorch multi head selection reBERT + reproduce "Joint entity recognition and relation extraction as a multi-head selection problem" for Chinese and English IE
Stars: ✭ 105 (+7.14%)
Mutual labels: chinese, relation-extraction
Information Extraction ChineseChinese Named Entity Recognition with IDCNN/biLSTM+CRF, and Relation Extraction with biGRU+2ATT 中文实体识别与关系提取
Stars: ✭ 1,888 (+1826.53%)
Mutual labels: relation-extraction, chinese-nlp
Nlp chinese corpus大规模中文自然语言处理语料 Large Scale Chinese Corpus for NLP
Stars: ✭ 6,656 (+6691.84%)
Mutual labels: chinese, chinese-nlp
Zhparserzhparser is a PostgreSQL extension for full-text search of Chinese language
Stars: ✭ 418 (+326.53%)
Mutual labels: chinese, chinese-nlp
Nlp4han中文自然语言处理工具集【断句/分词/词性标注/组块/句法分析/语义分析/NER/N元语法/HMM/代词消解/情感分析/拼写检查】
Stars: ✭ 206 (+110.2%)
Mutual labels: chinese, chinese-nlp
Deepke基于深度学习的开源中文关系抽取框架
Stars: ✭ 525 (+435.71%)
Mutual labels: chinese, relation-extraction
Chinesenre中文实体关系抽取,pytorch,bilstm+attention
Stars: ✭ 463 (+372.45%)
Mutual labels: chinese, relation-extraction
Lightnlp基于Pytorch和torchtext的自然语言处理深度学习框架。
Stars: ✭ 739 (+654.08%)
Mutual labels: chinese, relation-extraction
Chinese Xinhua📙 中华新华字典数据库。包括歇后语,成语,词语,汉字。
Stars: ✭ 8,705 (+8782.65%)
Mutual labels: chinese, chinese-nlp
CwsSource code for an ACL2016 paper of Chinese word segmentation
Stars: ✭ 81 (-17.35%)
Mutual labels: chinese
Chinese Copywriting GuidelinesChinese copywriting guidelines for better written communication/中文文案排版指北
Stars: ✭ 10,648 (+10765.31%)
Mutual labels: chinese
Py3aiml chinese官方py3AIML基于英文,现为其增加中文支持,并将代码注释翻译为中文。实测可正常解析带中文pattern和template的aiml文件。
Stars: ✭ 80 (-18.37%)
Mutual labels: chinese
LimesLink Discovery Framework for Metric Spaces.
Stars: ✭ 94 (-4.08%)
Mutual labels: semantic-web
Uer PyOpen Source Pre-training Model Framework in PyTorch & Pre-trained Model Zoo
Stars: ✭ 1,295 (+1221.43%)
Mutual labels: chinese
ChinesenlpDatasets, SOTA results of every fields of Chinese NLP
Stars: ✭ 1,206 (+1130.61%)
Mutual labels: chinese-nlp
Distre[ACL 19] Fine-tuning Pre-Trained Transformer Language Models to Distantly Supervised Relation Extraction
Stars: ✭ 75 (-23.47%)
Mutual labels: relation-extraction