SMRT-AIST / Fast_gicp
Licence: bsd-3-clause
A collection of GICP-based fast point cloud registration algorithms
Stars: ✭ 307
Projects that are alternatives of or similar to Fast gicp
Ndt omp
Multi-threaded and SSE friendly NDT algorithm
Stars: ✭ 291 (-5.21%)
Mutual labels: multithreading, point-cloud, pcl, registration
Cupoch
Robotics with GPU computing
Stars: ✭ 225 (-26.71%)
Mutual labels: point-cloud, gpu, cuda, registration
Open3d
Open3D: A Modern Library for 3D Data Processing
Stars: ✭ 5,860 (+1808.79%)
Mutual labels: gpu, cuda, registration
Tsne Cuda
GPU Accelerated t-SNE for CUDA with Python bindings
Stars: ✭ 1,120 (+264.82%)
Mutual labels: multithreading, gpu, cuda
Heteroflow
Concurrent CPU-GPU Programming using Task Models
Stars: ✭ 57 (-81.43%)
Mutual labels: multithreading, gpu, cuda
Occa
JIT Compilation for Multiple Architectures: C++, OpenMP, CUDA, HIP, OpenCL, Metal
Stars: ✭ 230 (-25.08%)
Mutual labels: multithreading, gpu, cuda
tiny-cuda-nn
Lightning fast & tiny C++/CUDA neural network framework
Stars: ✭ 908 (+195.77%)
Mutual labels: gpu, cuda
hipacc
A domain-specific language and compiler for image processing
Stars: ✭ 72 (-76.55%)
Mutual labels: gpu, cuda
LuisaRender
High-Performance Multiple-Backend Renderer Based on LuisaCompute
Stars: ✭ 47 (-84.69%)
Mutual labels: gpu, cuda
Popsift
PopSift is an implementation of the SIFT algorithm in CUDA.
Stars: ✭ 259 (-15.64%)
Mutual labels: gpu, cuda
MatX
An efficient C++17 GPU numerical computing library with Python-like syntax
Stars: ✭ 418 (+36.16%)
Mutual labels: gpu, cuda
gpu-monitor
Script to remotely check GPU servers for free GPUs
Stars: ✭ 85 (-72.31%)
Mutual labels: gpu, cuda
Kinectfusionlib
Implementation of the KinectFusion approach in modern C++14 and CUDA
Stars: ✭ 261 (-14.98%)
Mutual labels: point-cloud, cuda
QPT
[内测中]前向式Python环境快捷封装工具,快速将Python打包为EXE并添加CUDA、NoAVX等支持。
Stars: ✭ 308 (+0.33%)
Mutual labels: gpu, cuda
lbvh
an implementation of parallel linear BVH (LBVH) on GPU
Stars: ✭ 67 (-78.18%)
Mutual labels: gpu, cuda
opencv-cuda-docker
Dockerfiles for OpenCV compiled with CUDA, opencv_contrib modules and Python 3 bindings
Stars: ✭ 55 (-82.08%)
Mutual labels: gpu, cuda
pcljava
A port of the Point Cloud Library (PCL) using Java Native Interface (JNI).
Stars: ✭ 19 (-93.81%)
Mutual labels: point-cloud, pcl
Pycpd
Pure Numpy Implementation of the Coherent Point Drift Algorithm
Stars: ✭ 255 (-16.94%)
Mutual labels: point-cloud, registration
Awesome Cuda
This is a list of useful libraries and resources for CUDA development.
Stars: ✭ 274 (-10.75%)
Mutual labels: gpu, cuda
Hemi
Simple utilities to enable code reuse and portability between CUDA C/C++ and standard C/C++.
Stars: ✭ 275 (-10.42%)
Mutual labels: gpu, cuda
fast_gicp
This package is a collection of GICP-based fast point cloud registration algorithms. It constains a multi-threaded GICP as well as multi-thread and GPU implementations of our voxelized GICP (VGICP) algorithm. All the implemented algorithms have the PCL registration interface so that they can be used as an inplace replacement for GICP in PCL.
- FastGICP: multi-threaded GICP algorithm (~40FPS)
- FastGICPSingleThread: GICP algorithm optimized for single-threading (~15FPS)
- FastVGICP: multi-threaded and voxelized GICP algorithm (~70FPS)
- FastVGICPCuda: CUDA-accelerated voxelized GICP algorithm (~120FPS)
- NDTCuda: CUDA-accelerated D2D NDT algorithm (~500FPS)

 on melodic & noetic
on melodic & noetic
Installation
Dependencies
We have tested this package on Ubuntu 18.04/20.04 and CUDA 11.1.
CUDA
To enable the CUDA-powered implementations, set BUILD_VGICP_CUDA cmake option to ON.
ROS
cd ~/catkin_ws/src
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cd .. && catkin_make -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
Non-ROS
git clone https://github.com/SMRT-AIST/fast_gicp --recursive
mkdir fast_gicp/build && cd fast_gicp/build
cmake .. -DCMAKE_BUILD_TYPE=Release
# enable cuda-based implementations
# cmake .. -DCMAKE_BUILD_TYPE=Release -DBUILD_VGICP_CUDA=ON
make -j8
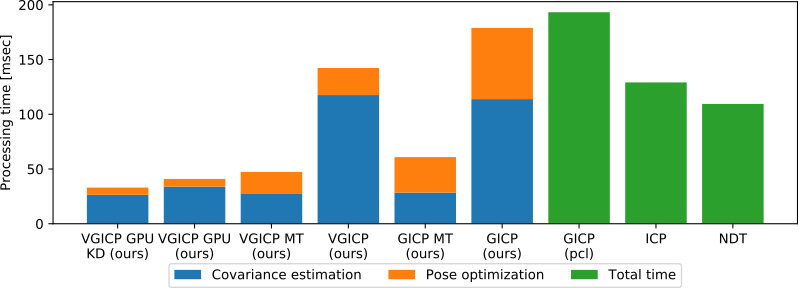
Benchmark
CPU:Core i9-9900K GPU:GeForce RTX2080Ti
roscd fast_gicp/data
rosrun fast_gicp gicp_align 251370668.pcd 251371071.pcd
target:17249[pts] source:17518[pts]
--- pcl_gicp ---
single:127.508[msec] 100times:12549.4[msec] fitness_score:0.204892
--- pcl_ndt ---
single:53.5904[msec] 100times:5467.16[msec] fitness_score:0.229616
--- fgicp_st ---
single:111.324[msec] 100times:10662.7[msec] 100times_reuse:6794.59[msec] fitness_score:0.204379
--- fgicp_mt ---
single:20.1602[msec] 100times:1585[msec] 100times_reuse:1017.74[msec] fitness_score:0.204412
--- vgicp_st ---
single:112.001[msec] 100times:7959.9[msec] 100times_reuse:4408.22[msec] fitness_score:0.204067
--- vgicp_mt ---
single:18.1106[msec] 100times:1381[msec] 100times_reuse:806.53[msec] fitness_score:0.204067
--- vgicp_cuda (parallel_kdtree) ---
single:15.9587[msec] 100times:1451.85[msec] 100times_reuse:695.48[msec] fitness_score:0.204061
--- vgicp_cuda (gpu_bruteforce) ---
single:53.9113[msec] 100times:3463.5[msec] 100times_reuse:1703.41[msec] fitness_score:0.204049
--- vgicp_cuda (gpu_rbf_kernel) ---
single:5.91508[msec] 100times:590.725[msec] 100times_reuse:226.787[msec] fitness_score:0.20557
See src/align.cpp for the detailed usage.
Test on KITTI
# Perform frame-by-frame registration
rosrun fast_gicp gicp_kitti /your/kitti/path/sequences/00/velodyne

Related packages
Papers
- Kenji Koide, Masashi Yokozuka, Shuji Oishi, and Atsuhiko Banno, Voxelized GICP for fast and accurate 3D point cloud registration, ICRA2021 [link]
Contact
Kenji Koide, [email protected]
Human-Centered Mobility Research Center, National Institute of Advanced Industrial Science and Technology, Japan [URL]
Note that the project description data, including the texts, logos, images, and/or trademarks,
for each open source project belongs to its rightful owner.
If you wish to add or remove any projects, please contact us at [email protected].